666ghj/BettaFish: The 39k-Star Multi-Agent System That Breaks Information Silos and Reads Public Opinion at Scale
Built from scratch in pure Python with no framework dependencies, BettaFish deploys four AI agents that crawl 30+ social platforms, debate findings through a novel Forum Engine, and deliver polished analytical reports. Here is how it works.

- BettaFish orchestrates four specialized AI agents that crawl, analyze, and debate public opinion across 30+ social platforms, then generate interactive HTML reports with zero human intervention.
- Its "Forum Engine" introduces an LLM moderator that forces agents to critique each other's findings across multiple rounds, preventing groupthink and single-model blind spots.
- The entire system is built from scratch in pure Python with no agent framework dependency, making it unusually transparent and extensible for a project of this complexity.
- Created by a BUPT undergraduate whose follow-up project attracted a $4M investment, BettaFish proves that one well-architected open-source tool can outperform enterprise sentiment platforms.
The Student Who Made GitHub's #1 Trending Spot a Habit
Guo Hangjiang, who codes under the handle "BaiFu" (666ghj on GitHub), was a senior at Beijing University of Posts and Telecommunications when he released BettaFish in mid-2024. The project hit GitHub's trending page, racked up 20,000 stars in its first week, and launched his career in a direction no one expected.
The name is a play on words. In Chinese, "Wei Yu" (the project's Chinese name) sounds like "small fish." A betta fish is tiny but famously aggressive. The metaphor fits: a lightweight system that punches far above its weight class.
Shanda Group founder Chen Tianqiao noticed BettaFish and later invested 30 million RMB (about $4M) into Guo's follow-up project, MiroFish. That backing validated the architecture. BettaFish was not a toy demo. It was the foundation for a real product pipeline.[1]
What BettaFish Actually Does
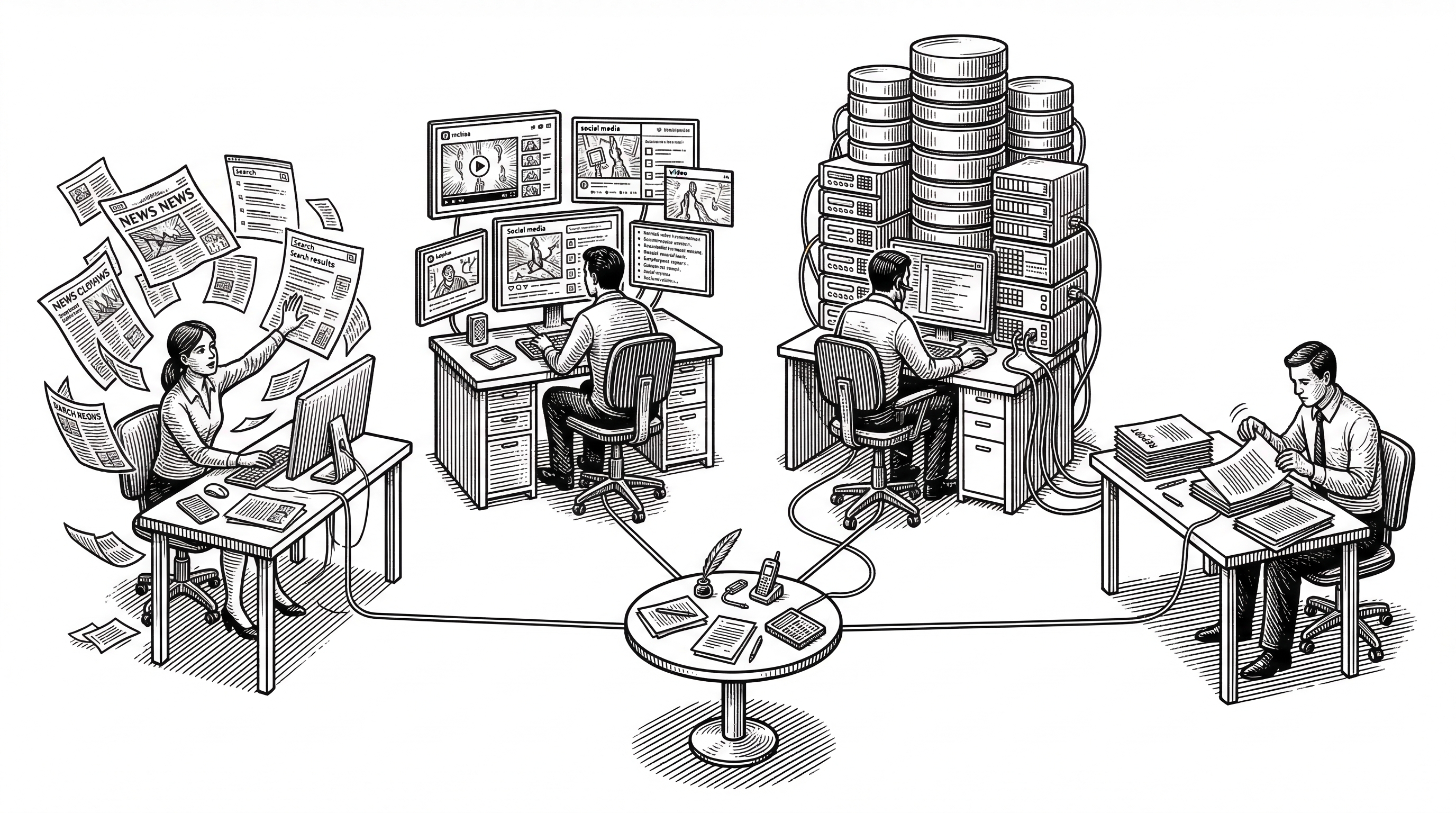
You type a question into a Flask web interface. Something like "What is the public perception of Wuhan University right now?" The system takes that query and fans it out to three research agents that work in parallel. No human in the loop. No drag-and-drop workflows.
Each agent has its own LLM, its own tool set, and its own research strategy. The Query Agent searches the open web. The Media Agent analyzes video and images from platforms like Douyin and Kuaishou. The Insight Agent mines a private PostgreSQL database filled by BettaFish's own crawler system, MindSpider.
After multiple rounds of research and debate (more on that shortly), a fourth agent, the Report Agent, compiles everything into a polished, interactive HTML report with charts, sentiment breakdowns, and sourced citations. The whole process is automated end to end.
The Four Agents, Dissected
Query Agent: The Open Web Researcher
The Query Agent is the broadest of the four. It uses web search APIs (Tavily, SerpAPI, and others configurable via the OpenAI-compatible interface) to comb through domestic and international news sources. It defaults to DeepSeek as its LLM, reflecting a deliberate choice to use cost-effective reasoning models for high-volume search tasks.
Internally, it follows a node-based pipeline: search, format, summarize, reflect, repeat. Each cycle refines the search strategy based on what was found in the previous round. The code lives in QueryEngine/, with a clean separation between nodes/, tools/, and prompts/.
Media Agent: The Multimodal Analyst
This is where BettaFish goes beyond text. The Media Agent processes short-form video content from Douyin, Kuaishou, and other platforms. It can also extract structured data from search engine result pages: weather cards, stock tickers, calendar events.
It runs on Gemini 2.5 Pro by default, which makes sense given the multimodal heavy lifting. The architecture mirrors the Query Agent (same node/tool/prompt separation), but the tool set is entirely different, focused on video transcription, image understanding, and structured data extraction.
Insight Agent: The Database Miner
The Insight Agent connects to a private PostgreSQL (or MySQL) database populated by MindSpider, BettaFish's built-in crawler. This is the agent that turns BettaFish from a search wrapper into an actual intelligence platform.
It includes a Qwen-powered keyword optimizer that translates natural language queries into efficient SQL, and it plugs directly into BettaFish's sentiment analysis models. The toolset in InsightEngine/tools/ includes keyword_optimizer.py, search.py, and sentiment_analyzer.py. Default LLM: Kimi K2.
Report Agent: The Publisher
The Report Agent does not just summarize. It selects a template, plans a document layout, budgets word counts per chapter, generates structured IR (Intermediate Representation) JSON blocks, validates them against a formal schema, then renders interactive HTML. The IR schema supports 16 block types including tables, SWOT analyses, PEST analyses, KPI grids, and embedded charts.
This is a multi-round generation process. Each chapter is produced separately, validated, and stitched together by a dedicated "stitcher" module. The output is not a markdown dump. It is a fully styled, interactive document with navigation, charts rendered as SVG, and optional PDF export via WeasyPrint.
The Forum Engine: Where Agents Argue
This is the most distinctive part of BettaFish's architecture. Most multi-agent systems run agents in parallel and then merge results. BettaFish adds a debate layer.
The Forum Engine (ForumEngine/) monitors log files from all three research agents. After every five agent "speeches" (summary outputs), it triggers an LLM moderator that reads all findings so far, identifies gaps and contradictions, and generates guidance for the next research round.
The moderator is a separate LLM instance (Qwen by default). It does not just merge. It challenges. It might tell the Query Agent to dig deeper on a specific angle, or ask the Media Agent to verify a claim the Insight Agent surfaced from the database. Agents read the moderator's output via a shared forum_reader tool in utils/.
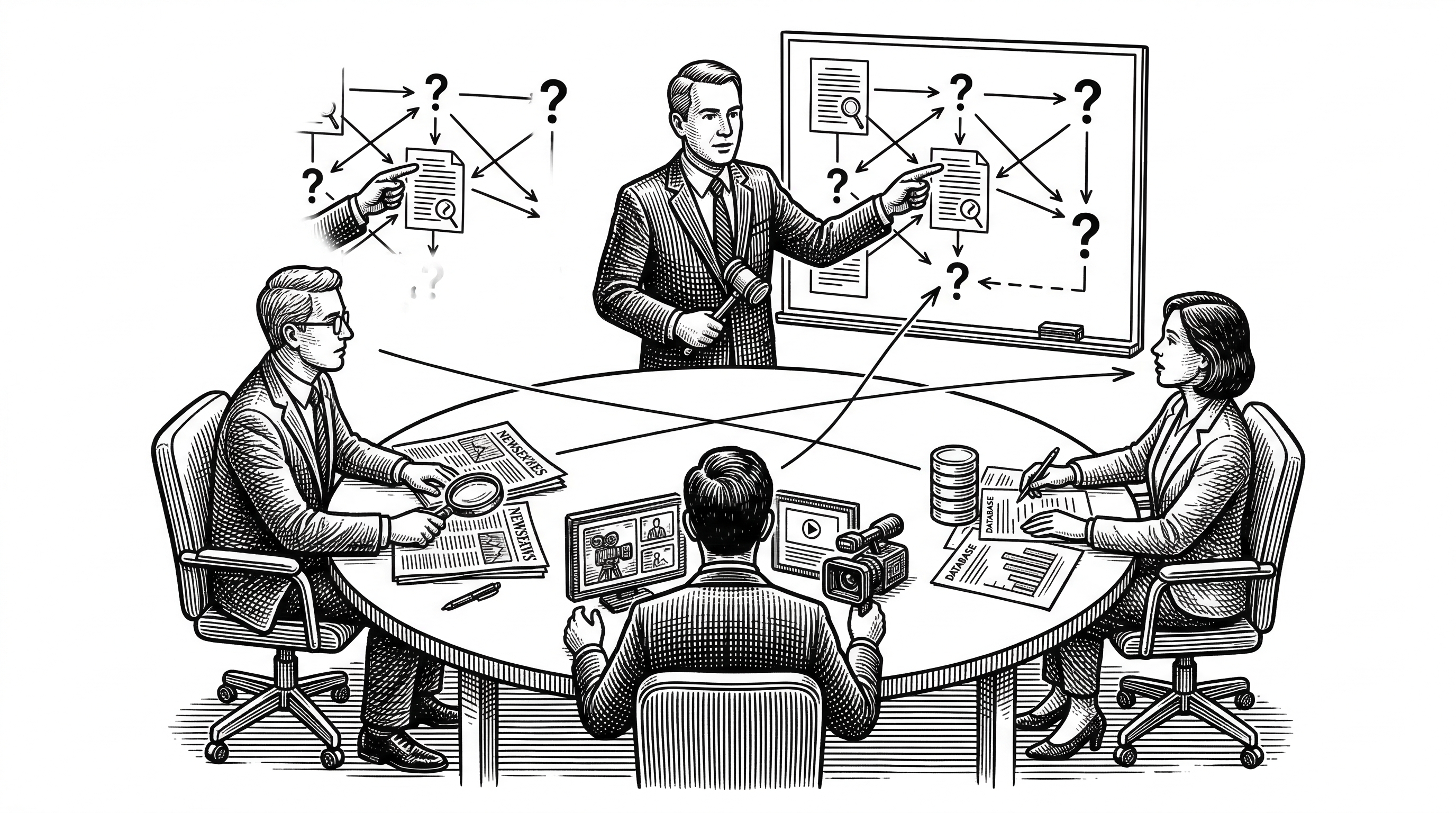
This is a meaningful architectural choice. Single-LLM systems develop blind spots. Merge-only multi-agent systems produce mushy consensus. The Forum Engine introduces productive friction. It is chain-of-thought collision: agents with different data sources and different reasoning models are forced to reconcile their findings through structured debate.
The implementation is surprisingly lightweight. The LogMonitor class watches three log files, parses summary nodes, buffers speeches, and triggers the ForumHost class which calls the moderator LLM. The whole mechanism lives in just two files: monitor.py and llm_host.py.
MindSpider: The Crawler That Feeds the System
BettaFish is not just an analysis layer on top of search APIs. MindSpider, its built-in crawler subsystem, is a full social media data collection pipeline.
It operates in two phases. BroadTopicExtraction pulls today's trending topics and hot news. DeepSentimentCrawling then dives into specific platforms, crawling not just posts but the full comment threads underneath them. Supported platforms include Weibo, Xiaohongshu (Little Red Book), Douyin, Kuaishou, and others.
The crawled data lands in a PostgreSQL database with a well-defined schema (MindSpider/schema/). The Insight Agent then mines this database during analysis. This creates a feedback loop: the crawler builds an ever-growing private dataset, and the analysis agents get smarter with each run because they have more historical data to draw from.
Sentiment Analysis: Not Just LLM Vibes
One of BettaFish's quieter strengths is its sentiment analysis stack. It does not rely solely on LLM-based sentiment classification. The SentimentAnalysisModel/ directory contains five distinct approaches.
There is a LoRA-finetuned BERT model for Chinese text. A LoRA-finetuned GPT-2. A multilingual sentiment model for cross-language analysis. A small-parameter Qwen3 finetune. And a traditional machine learning pipeline using SVM and other classical methods.
This composite approach matters. LLMs are good at nuanced sentiment but expensive and slow at scale. Traditional ML models handle bulk classification cheaply. The system can use both, matching the right tool to the right volume of data.
The Report Pipeline: From IR to Interactive HTML
The Report Engine deserves a closer look because it is more sophisticated than most open-source report generators. It operates on a formal Intermediate Representation (IR).
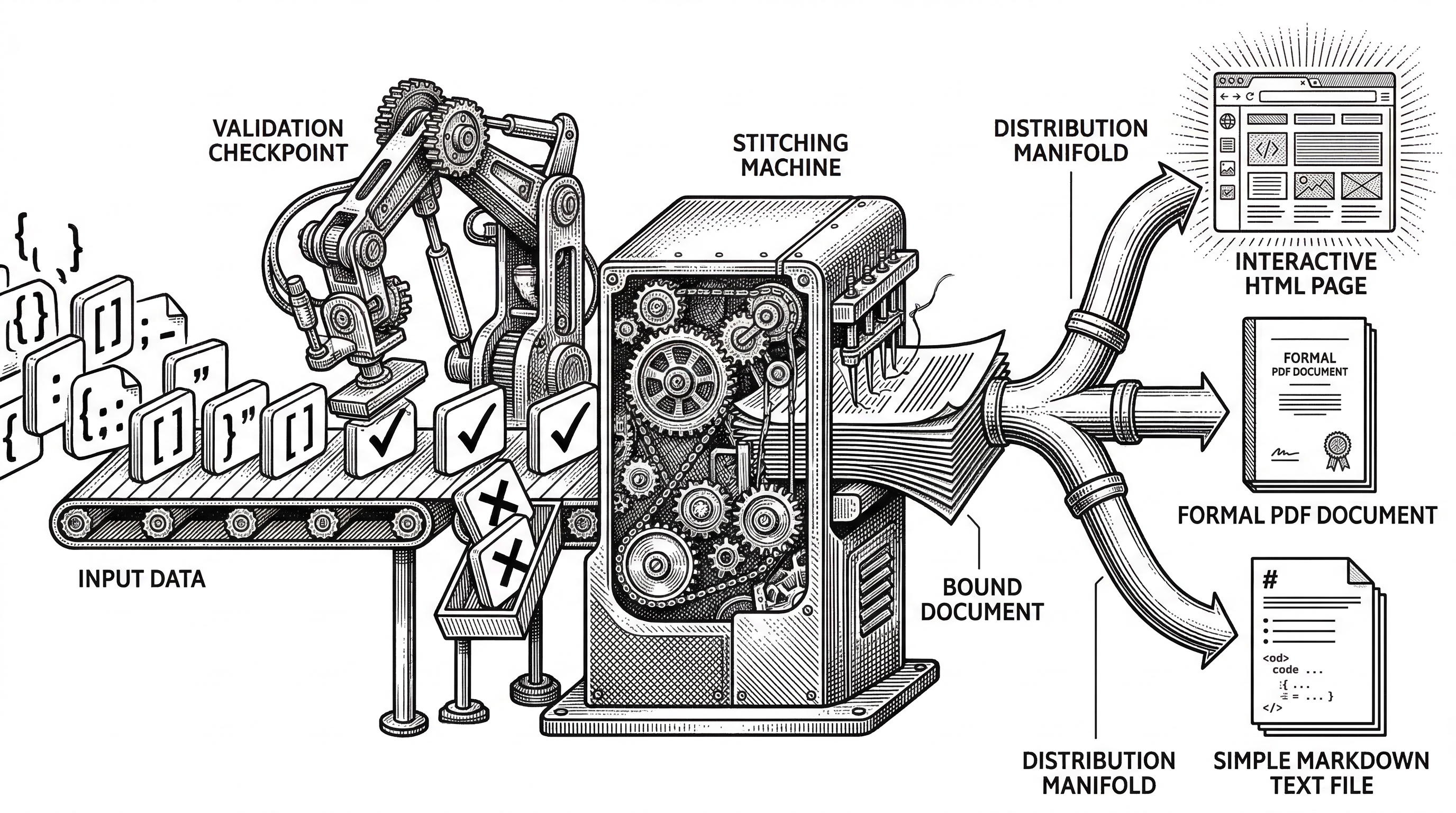
The IR schema (ReportEngine/ir/schema.py) defines 16 allowed block types and 12 inline mark types. Each chapter is generated as validated JSON, not free-form text. The validator.py module checks every chapter against the schema before it is accepted. If a block fails validation, the agent retries.
Once all chapters are validated, the stitcher (core/stitcher.py) assembles them into a complete Document IR, adds anchors and metadata, and passes the result to one of three renderers: HTML (interactive, with charts), PDF (via WeasyPrint with layout optimization), or Markdown.
This is not a common pattern in open-source AI projects. Most systems dump markdown. BettaFish produces structured, validated, renderable documents. The report template library includes specialized formats like "Corporate Brand Reputation Analysis" and others, and users can upload custom templates.
The Stack: Pragmatic and Portable
BettaFish runs on a surprisingly conventional stack. Flask for the web interface, with Socket.IO for real-time progress updates. PostgreSQL for the data layer. Streamlit for standalone single-agent apps. Docker Compose for deployment.
Each agent uses an OpenAI-compatible API interface, which means you can swap in any LLM provider. The recommended lineup is DeepSeek for Query Agent, Gemini 2.5 Pro for Media and Report Agents, Kimi K2 for Insight Agent, and Qwen for the Forum moderator. But any OpenAI-format endpoint works.
Configuration uses Pydantic Settings with a single .env file at the project root. Sub-agents inherit from the root config automatically. This is a clean pattern that makes deployment predictable.
How BettaFish Compares
BettaFish sits in a crowded space where enterprise SaaS tools, research prototypes, and open-source projects all claim to do "sentiment analysis" or "social listening." Here is where it actually falls on the map.
| Tool | Approach | Data Sources | Agent Collaboration | Output | Cost |
|---|---|---|---|---|---|
| BettaFish | Multi-agent + Forum debate | 30+ platforms + private DB | LLM moderator + multi-round | Interactive HTML/PDF reports | Open source (GPL-2.0) |
| Brandwatch / Meltwater | SaaS dashboards | Broad social + news | None | Dashboards + CSV exports | $1,000+/mo |
| SocialPulse | Subreddit sensemaking | Reddit only | None | Interactive topic explorer | Open source |
| Perplexity / ChatGPT | Single-model search + synthesis | Web search | None | Text responses | Subscription |
| CrewAI / AutoGen | Agent frameworks | Whatever you build | Role-based collaboration | Whatever you build | Open source |
The key differentiator is not any single feature. It is the integration. BettaFish is the only open-source tool that combines its own crawlers, a private database, multiple specialized agents, a debate mechanism, fine-tuned sentiment models, and a formal report generation pipeline in one system. Enterprise tools have broader data access but no agent intelligence. Agent frameworks have the orchestration but no domain-specific tooling.
What the Community Has Built
With 7,300+ forks, BettaFish has become a template for building domain-specific analysis systems. The README explicitly encourages this: swap the agent tool sets and prompts, and you can turn BettaFish into a financial market analyzer, a product feedback system, or a competitive intelligence tool.
Community discussions on linux.do feature detailed comparisons with Manus, MiniMax, ChatGPT, and Perplexity, with users reporting that BettaFish produces deeper and more structured analysis than any of the commercial alternatives for Chinese-language social media topics.[2]
"What Shanda valued was not BaiFu's technical level per se. It was his complete planning of the entire process from data collection, analysis to prediction, and his ability to identify and define real and valuable problems and try to solve them in new AI-based ways."
Limitations and Open Questions
BettaFish is not without rough edges. The GPL-2.0 license means any derivative work must also be open source, which limits commercial adoption. The system requires multiple LLM API keys and a running database, making the initial setup more involved than a simple pip install.
The crawler subsystem (MindSpider) raises the usual ethical and legal questions about scraping social media at scale. The project's disclaimer explicitly states it is for academic and educational use only, not commercial deployment. Whether that disclaimer holds up under scrutiny depends on jurisdiction.
Performance at scale is also an open question. Running four LLM agents plus a moderator plus sentiment models on large datasets burns API credits quickly. The system's cost efficiency depends heavily on which models you configure and how many debate rounds you allow.
What It Means for the Space
BettaFish is one of the clearest examples of what a single skilled developer can build with modern AI tools. It is a complete, functional intelligence platform built without any agent framework dependency, without a team of engineers, and without enterprise backing (at least initially).
The Forum Engine pattern is worth watching. Forcing agents to debate rather than just merge is a simple but powerful idea that could apply to any multi-agent system. If your agents never disagree, they are probably just an expensive way to average out one model's opinion.
The project also demonstrates that the real moat in AI-powered analysis is not the model. It is the pipeline. Anyone can call GPT-4. The value is in crawling the data, structuring it, running domain-specific models on it, orchestrating the analysis, and producing validated outputs. BettaFish does all of that, and it does it in the open.