BitNet: The 1-Bit Revolution That Runs a 100B Model on Your Laptop
Microsoft's bitnet.cpp replaces floating-point math with ternary lookup tables, letting a 100-billion-parameter model run at human reading speed on a single CPU. This changes who gets to use large language models.
- BitNet b1.58 trains models natively with ternary weights {-1, 0, 1}, replacing 16-bit floating-point math with 1.58-bit lookup tables that cut memory by roughly 10x.
- bitnet.cpp achieves 2.37x to 6.17x speedups on x86 CPUs and 55-82% energy reductions, making a 100B-parameter model run at 5-7 tokens per second on a single machine.
- Microsoft's first official model, BitNet-b1.58-2B-4T, matches full-precision competitors at the 2B scale while consuming 12x less energy per inference.
- The project signals a possible future where LLM inference shifts from GPU clusters to commodity hardware, fundamentally changing the economics of AI deployment.
The Weight of Weights
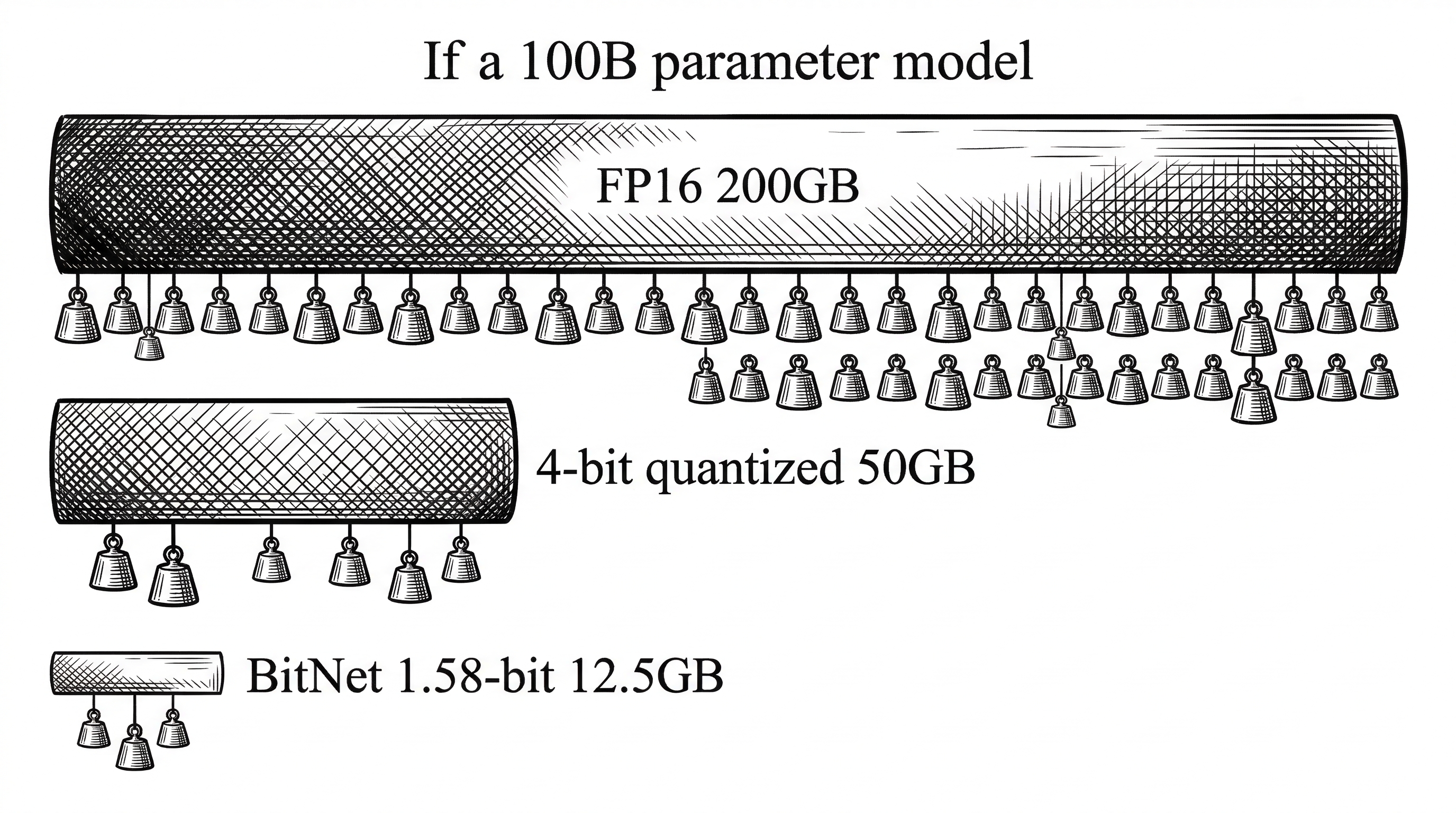
Every large language model carries a burden: its parameters. A 70-billion-parameter model stored in half-precision floating point (FP16) demands roughly 140 GB of memory. That is multiple high-end GPUs just to hold the weights, before you even run inference.
The industry's response has been post-training quantization. Take a model trained in FP16, squeeze it down to 4-bit or 8-bit integers, accept the quality loss, and move on. It works. But it is a compression hack applied after the fact, not a fundamental rethinking of how models store knowledge.
Microsoft Research asked a different question: what if the model never needed 16-bit weights in the first place?
The Ternary Breakthrough
In February 2024, a team at Microsoft Research published "The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits." The paper introduced BitNet b1.58, a transformer architecture where every weight is constrained to exactly three values: -1, 0, or 1.
The name "1.58-bit" comes from information theory. Three possible values require log2(3) = 1.58 bits to encode. It is not truly 1-bit (which would be binary, just -1 and 1). The inclusion of zero turns out to be crucial. Zero lets the model learn sparsity natively, effectively deciding which connections matter and which can be ignored entirely.
The key insight is that these weights are not quantized after training. They are trained this way from scratch. Microsoft introduced BitLinear, a drop-in replacement for the standard nn.Linear layer. During the forward pass, weights are quantized to {-1, 0, 1} using absmean quantization. The model learns to work within these constraints from the very first gradient update.
"BitNet b1.58 matches full-precision LLaMA LLM at 3B model size in terms of perplexity, while being 2.71 times faster and using 3.55 times less GPU memory."
Why Lookup Tables Change Everything
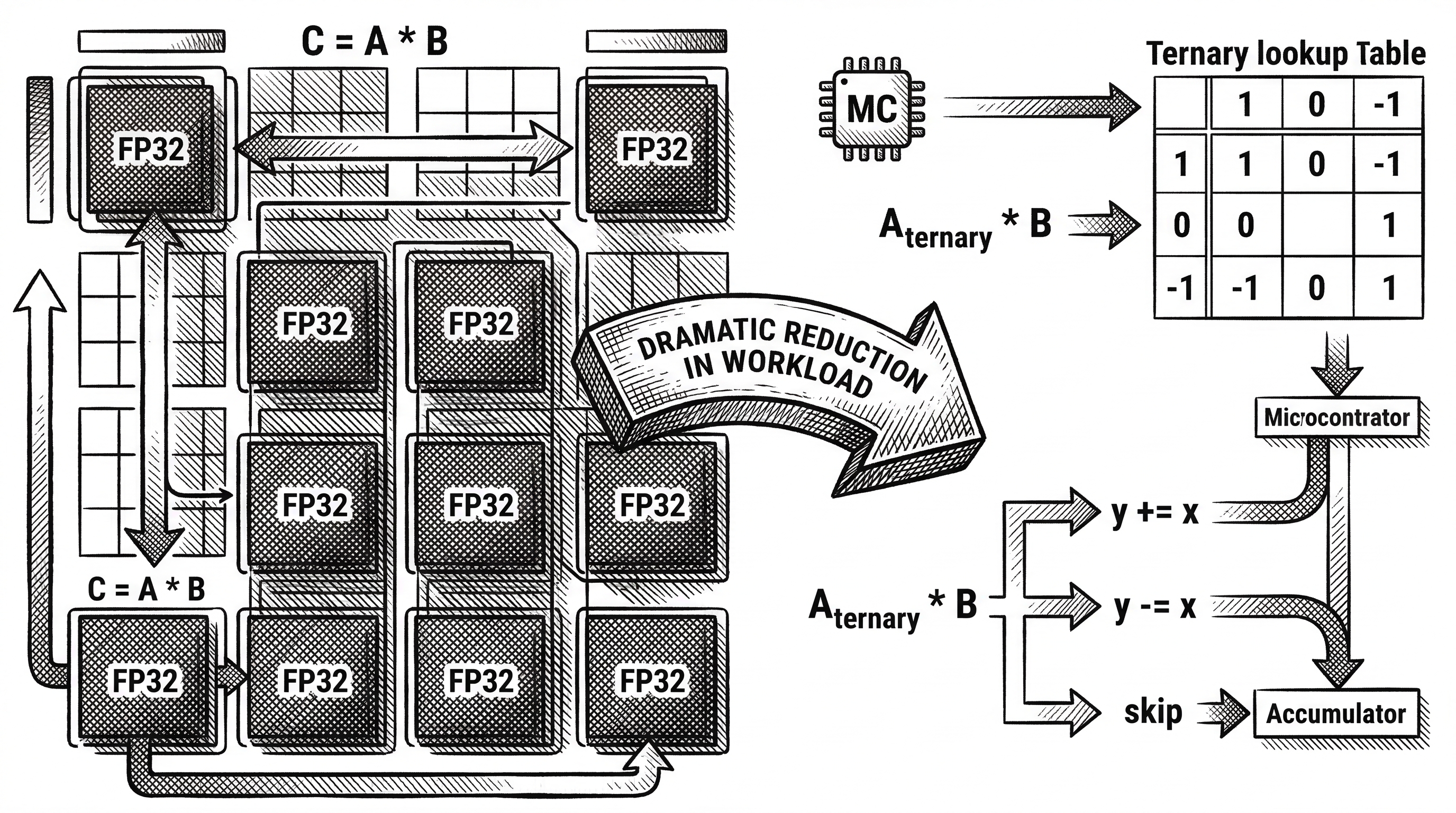
When every weight is -1, 0, or 1, matrix multiplication collapses into something far simpler. You no longer need floating-point multiply-accumulate operations. You just add, subtract, or skip.
bitnet.cpp takes this further with lookup-table (LUT) kernels, building on the T-MAC methodology. Instead of computing each weight-activation product individually, the framework precomputes results for groups of weights and stores them in tables. At inference time, a matrix "multiply" becomes a series of table lookups.
The project ships three kernel types. I2_S is a 2-bit integer kernel that works across both x86 and ARM. TL1 is a ternary lookup kernel optimized for ARM's NEON instructions. TL2 targets x86 with AVX2 acceleration. Each is hand-tuned for its target architecture.
The Numbers That Matter
On ARM CPUs, bitnet.cpp delivers speedups of 1.37x to 5.07x over equivalent FP16 inference, with energy consumption dropping 55.4% to 70.0%. Larger models see bigger gains because the memory bandwidth bottleneck hurts FP16 more as model size grows.
The x86 results are even more dramatic: 2.37x to 6.17x speedups with energy reductions of 71.9% to 82.2%. The latest optimization round, released in January 2026, added parallel kernel implementations with configurable tiling and embedding quantization. That squeezed out another 1.15x to 2.1x on top of the original gains.
The headline number: a 100-billion-parameter BitNet b1.58 model runs on a single CPU at 5-7 tokens per second. That is human reading speed. No GPU required.
| Platform | Speedup vs FP16 | Energy Reduction | Key Kernel |
|---|---|---|---|
| ARM (Apple M-series, Snapdragon) | 1.37x to 5.07x | 55.4% to 70.0% | TL1 (NEON) |
| x86 (Intel, AMD) | 2.37x to 6.17x | 71.9% to 82.2% | TL2 (AVX2) |
| NVIDIA GPU | Batch optimized | Significant | Custom CUDA |
The First Official Model
In April 2025, Microsoft released BitNet-b1.58-2B-4T: a 2.4-billion-parameter model trained from scratch on 4 trillion tokens. It was the first production-quality model natively trained with ternary weights, not a research demo.
The benchmarks were striking. On ARC-Challenge (commonsense reasoning), it scored 68.5%, matching Llama 3 3B at 68.2% despite being a smaller model. On HellaSwag, it hit 84.3%, outperforming Qwen 1.8B. Its memory footprint was 0.4 GB compared to 2-4.8 GB for similar-sized competitors.
The energy story is where it gets wild. Each inference costs approximately 0.028 joules, compared to 0.347 joules for Qwen 2.5. That is roughly 12x more efficient. Run the math on a datacenter serving millions of requests per day and the cost difference is enormous.

Architecture Under the Hood
bitnet.cpp is built on top of llama.cpp, the widely adopted C/C++ inference engine. This is not a coincidence. By forking the most battle-tested local inference framework in the ecosystem, Microsoft inherited its broad hardware support, GGUF model format, and active community.
The project adds its own optimized kernels in src/ggml-bitnet-lut.cpp (lookup table path) and src/ggml-bitnet-mad.cpp (multiply-add path). The GPU story lives in a separate gpu/ directory with custom CUDA kernels, a dedicated weight packer, and its own model loader.
The setup pipeline is straightforward. You clone the repo, install dependencies via conda and pip, download a model from HuggingFace, and run setup_env.py to convert weights to the optimized GGUF format. Then run_inference.py handles the actual text generation. There is also run_inference_server.py for serving.
# Clone and setup
git clone --recursive https://github.com/microsoft/BitNet.git
cd BitNet
conda create -n bitnet-cpp python=3.9
conda activate bitnet-cpp
pip install -r requirements.txt
# Download and convert model
huggingface-cli download microsoft/BitNet-b1.58-2B-4T-gguf \
--local-dir models/BitNet-b1.58-2B-4T
python setup_env.py -md models/BitNet-b1.58-2B-4T -q i2_s
# Run inference
python run_inference.py \
-m models/BitNet-b1.58-2B-4T/ggml-model-i2_s.gguf \
-p "You are a helpful assistant" -cnvThe Competitive Landscape
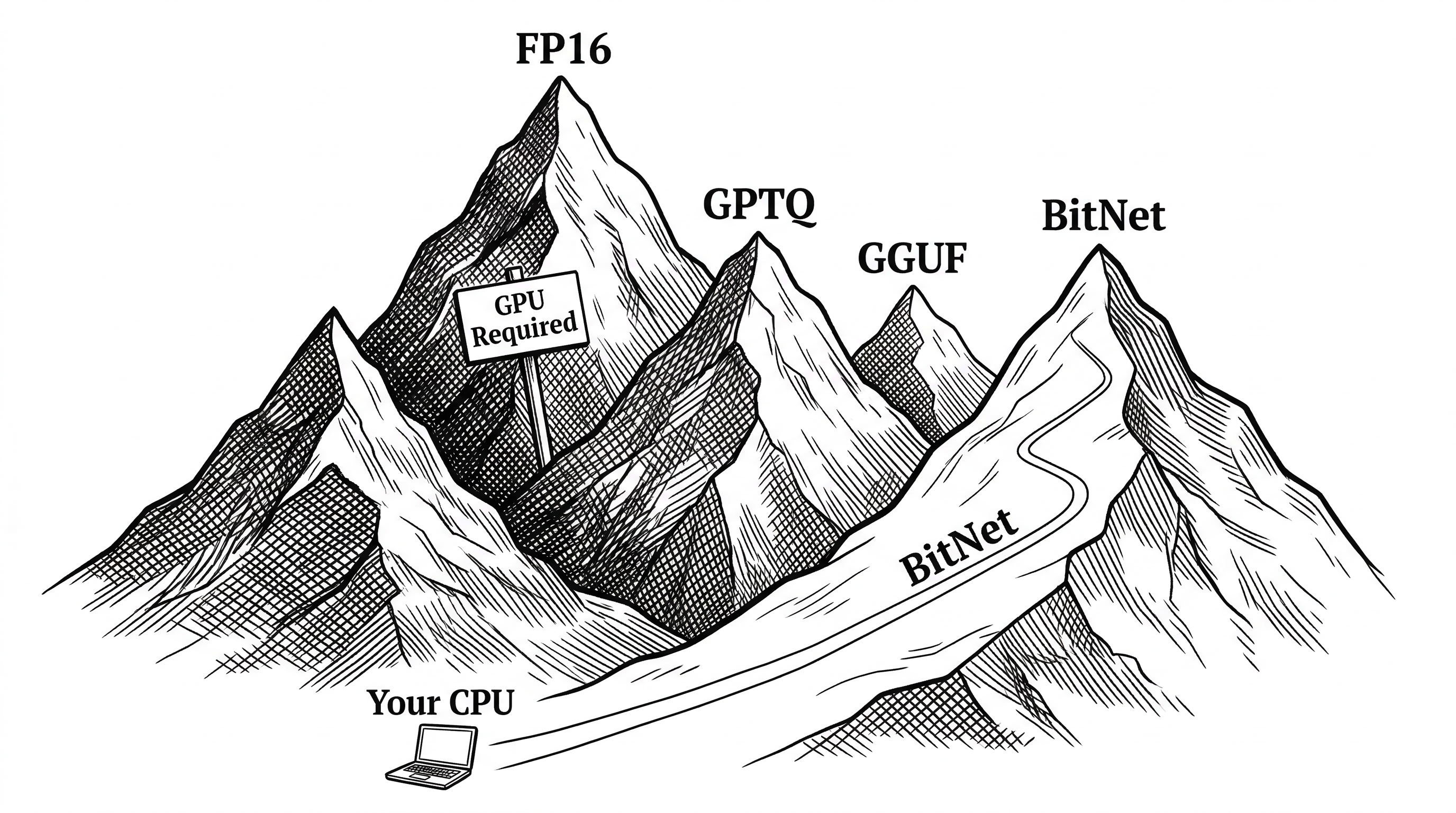
BitNet does not exist in isolation. The local inference space is crowded and moving fast. Understanding where it fits requires looking at what it replaces and what it complements.
| Approach | Bit Width | Training | Quality Trade-off | Hardware Need |
|---|---|---|---|---|
| FP16 (baseline) | 16 bits | Standard | None (reference) | High-end GPU |
| GPTQ / AWQ (post-quant) | 4 bits | Post-training | Small but measurable | GPU preferred |
| GGUF Q4 (llama.cpp) | 4 bits | Post-training | Small but measurable | CPU or GPU |
| BitNet b1.58 | 1.58 bits | Native (from scratch) | Minimal (matches FP16) | CPU alone works |
The critical distinction: every other quantization method starts with a full-precision model and compresses it. BitNet trains natively at low precision. The model never had full-precision weights to lose. This is why it can match FP16 quality at 1.58 bits when post-training quantization to similar depths would destroy model quality.
llama.cpp remains the dominant local inference engine, and bitnet.cpp wisely builds on top of it rather than competing. The ecosystem around GGUF quantization is massive. BitNet's bet is that as more models are natively trained with ternary weights, its specialized kernels will outperform general-purpose quantization.
The Catch: Training Is Expensive
There is a significant caveat. You cannot take an existing FP16 model and convert it to BitNet. The ternary constraint must be present during training. That means someone has to pay the full cost of pre-training a model from scratch with BitLinear layers.
As of now, the ecosystem of natively-trained 1.58-bit models is small. Microsoft's official 2B model exists. The community has produced a few others: a 0.7B model, a 3.3B model, a Llama3-8B variant trained on 100B tokens, and the Falcon3 family. But there is no 1.58-bit equivalent of Llama 3.1 405B or Mixtral 8x22B. Not yet.
This is the chicken-and-egg problem. Efficient inference frameworks need models. Models need training investment. Microsoft releasing bitnet.cpp and their 2B-4T model is a deliberate attempt to break the cycle by proving the approach works end-to-end.
GPU Support Arrives
The original bitnet.cpp release in October 2024 was CPU-only. That was the point: show that ternary models can run fast on commodity hardware. But production serving demands GPUs for batch throughput.
In May 2025, Microsoft added official GPU inference kernels. The gpu/ directory contains custom CUDA implementations with a dedicated weight packing pipeline. The architecture is cleanly separated: convert_safetensors.py handles model conversion, pack_weight.py optimizes the weight layout for GPU memory access patterns, and bitnet_kernels/ contains the actual CUDA code.
This dual CPU/GPU story makes BitNet relevant across the full deployment spectrum: laptops, edge devices, and datacenters.
What BitNet a4.8 Hints At
In November 2024, Microsoft published "BitNet a4.8: 4-bit Activations for 1-bit LLMs." The paper extended the ternary weight idea to also quantize activations to 4 bits during inference.
Activations are the intermediate values flowing through the network during a forward pass. They are typically stored in FP16 even when weights are quantized. By reducing activations to 4 bits, Microsoft squeezed even more performance out of the pipeline without significant quality loss.
This research direction suggests the team sees the current framework as just the beginning. If both weights and activations can be aggressively quantized, the throughput gains compound. NPU (Neural Processing Unit) support is listed as "coming next" in the README, hinting at mobile and embedded deployment.
Who Should Care
If you run AI inference at scale, BitNet is a cost story. A 12x reduction in energy per inference translates directly to operational savings. Even if the current model selection is limited, the trajectory is clear.
If you build edge or mobile AI products, BitNet is an access story. Running a capable LLM on a CPU opens deployment targets that GPU-dependent models cannot reach. IoT devices, smartphones, embedded systems.
If you are a researcher, BitNet is a paradigm story. Native low-bit training challenges the assumption that models need high-precision weights. The ternary constraint forces the network to find fundamentally different representations of knowledge.
And if you simply want to run a decent AI model on your laptop without a $2,000 GPU, BitNet is a freedom story.
The Skeptic's View
Not everything is rosy. The model ecosystem is thin. The largest natively-trained ternary model is 8B parameters, far from the frontier of 70B-405B models where LLM capabilities really differentiate. Training from scratch is expensive and slow to iterate on.
There is also a quality ceiling question. The 2B model matches competitors at its size class, but can ternary weights scale to the reasoning depth of much larger models? The 100B benchmark on bitnet.cpp used a dummy model for speed testing, not a real trained model. Nobody has publicly trained and evaluated a 100B+ ternary model yet.
Finally, the framework is tightly coupled to specific model architectures. You cannot just drop any model into bitnet.cpp. It requires models built with BitLinear layers and converted to its specific GGUF variant. The walled garden is small, even if the door is open.
"BitNet b1.58 2B4T demonstrates that native 1-bit LLMs can achieve performance comparable to leading open-weight, full-precision models of similar size, while offering substantial advantages in computational efficiency."
What Happens Next
The research trajectory points in a clear direction. Ternary weights work. The inference framework exists. GPU support is live. The missing piece is scale: larger natively-trained models that can compete with the 70B+ frontier.
Microsoft is investing. The progression from research paper (October 2023) to inference framework (October 2024) to official model (April 2025) to GPU kernels (May 2025) to further CPU optimizations (January 2026) shows sustained commitment. This is not a one-paper wonder.
The broader implication is that the GPU moat around LLM inference may not be as permanent as it looks. If ternary models can match FP16 quality at scale, and if lookup-table kernels can deliver competitive throughput on CPUs, the economics of AI deployment shift dramatically. Not everyone can afford H100 clusters. Everyone has a CPU.
bitnet.cpp is a bet that the future of LLM inference is not about bigger GPUs. It is about smarter math.