Fish Speech S2: The Open-Source TTS That Beat the Closed-Source Giants
Fish Audio's 4B-parameter Dual-AR model trained on 10 million hours of audio achieves the lowest word error rate of any TTS system, open or closed. Inline emotion tags, 50-language support, and sub-100ms streaming make it the new benchmark.

- Fish Audio S2 achieves the lowest word error rate on Seed-TTS Eval of any system tested, beating Qwen3-TTS, MiniMax Speech-02, and ByteDance's own Seed-TTS.
- The Dual-Autoregressive architecture splits a 4B Slow AR (time axis) from a 400M Fast AR (depth axis), making production streaming at 0.195 RTF possible on a single H200.
- Free-form natural-language inline tags like [whisper], [laugh], and [super happy] let you control emotion at the word level without a predefined tag vocabulary.
- Trained on 10M+ hours across ~50 languages, S2 won best WER in 11 of 24 languages and best speaker similarity in 17 of 24 on MiniMax's multilingual testset.
From Dorm Room GPUs to State of the Art
Shijia Liao graduated from the University of Maryland in 2023 and joined NVIDIA to scale Vision Foundation Models across GPU clusters. Then he quit. He spent countless nights prototyping Fish Audio on a home rig of 4090 GPUs with a four-person Gen Z founding team.
That team had serious open-source credentials. Before Fish Audio existed as a company, Liao led or contributed to So-VITS-SVC, GPT-SoVITS, and Bert-VITS2. These projects are still widely used in creative coding and research communities. Fish Speech was always meant to be the system that turned those experiments into something production-ready.
The growth numbers tell the story. Between January and April 2025, Fish Audio scaled annualized revenue from $400,000 to over $5 million. Monthly active users jumped from 50,000 to 420,000. All of this happened before S2 was even released.

What Makes S2 Different
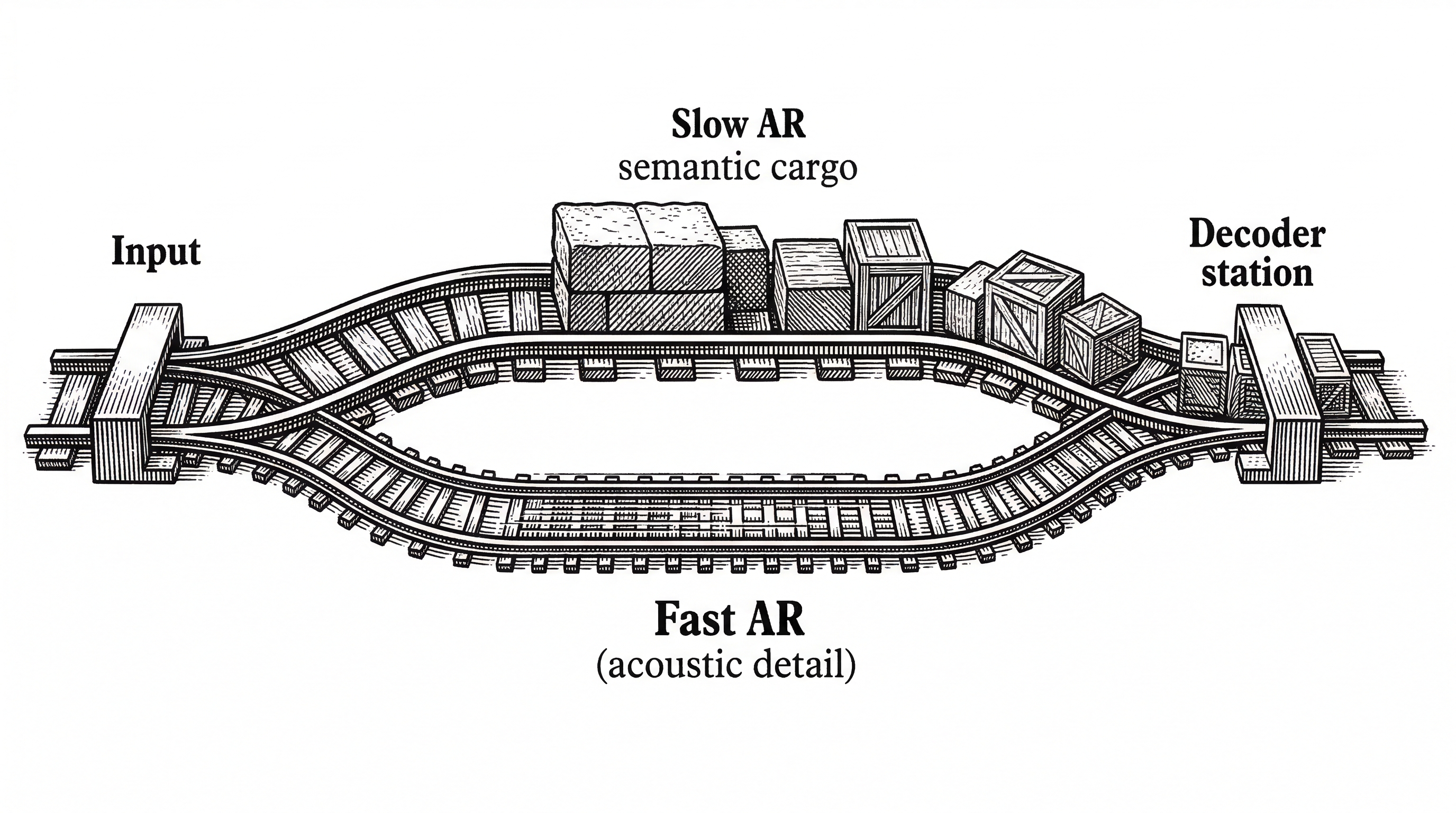
Most TTS systems treat voice generation as a monolithic pipeline: text goes in, audio comes out, and you hope the middle does something reasonable. Fish Audio S2 rethinks the architecture from the ground up with a technique called Dual-Autoregressive generation.
The insight is that speech has two axes that matter. The time axis determines what gets said and when. The depth axis determines the acoustic richness of each moment. S2 assigns separate models to each axis, with radically different parameter budgets.
The Dual-AR Architecture
The Slow AR is a 4-billion-parameter decoder-only transformer. It operates along the time axis and predicts tokens from the primary semantic codebook at roughly 21 frames per second. This is the expensive, high-stakes model. It decides the content, rhythm, and prosody of the speech.
The Fast AR is a 400-million-parameter model that runs at each time step. Given the semantic token from Slow AR, it autoregressively generates the remaining 9 codebooks along the depth axis. These residual codebooks reconstruct fine-grained acoustic detail: timbre, breathiness, room characteristics.
This asymmetric split is the key architectural decision. The time axis gets the heavy model because semantic content is hard. The depth axis gets the lightweight model because acoustic detail, given good semantics, is comparatively easy. The result is an efficient system that does not sacrifice fidelity.
Under the hood, the audio codec is based on Descript Audio Codec (DAC) with 10 codebook layers using Residual Vector Quantization (RVQ). The entire setup is structurally isomorphic to a standard autoregressive LLM. That seemingly academic point has massive practical consequences.
GRPO: Reinforcement Learning for Voice
Pre-training on 10 million hours of audio gets you a strong base model. But the gap between "good" and "indistinguishable from human" requires alignment. Fish Audio S2 uses Group Relative Policy Optimization (GRPO) for this final push.
GRPO is a variant of reinforcement learning from human feedback, originally developed for LLMs. The clever adaptation here is that the same models used to filter and annotate training data during pre-training are directly reused as reward models during RL. This eliminates the distribution mismatch that plagues most RLHF setups.
The reward signal combines four components: semantic accuracy (measured via ASR word error rate), instruction adherence (does it actually whisper when you say [whisper]?), acoustic preference scoring (overall audio quality), and timbre similarity (does the cloned voice match the reference?). Each signal pulls the model toward a different dimension of quality.
"S2 uses GRPO for post-training alignment. The same models used to filter and annotate training data are directly reused as reward models during RL, eliminating distribution mismatch between pre-training data and post-training objectives."
Inline Emotion Control
Most TTS systems that support emotion control give you a dropdown menu: happy, sad, angry, neutral. Maybe a few more if you are lucky. Fish Audio S2 throws out the dropdown entirely.
Instead, you embed free-form natural-language instructions directly into the text at the exact position where you want the emotional shift. Write [whisper in small voice] before a word and that word gets whispered. Write [professional broadcast tone] at the start of a paragraph and the entire paragraph shifts register. Write [laugh] and the model laughs.
This is not a fixed tag vocabulary. The model accepts arbitrary textual descriptions and interprets them. The Fish Instruction Benchmark measures this: S2 scores a 93.3% tag adherence rate with 4.51 out of 5.0 quality.

The Benchmark Blitz
Numbers do not lie, and S2's numbers are striking. On the Seed-TTS Eval benchmark, it achieves a Chinese WER of 0.54% and an English WER of 0.99%. Both are the best scores recorded by any system, open or closed.
For context, Alibaba's Qwen3-TTS scores 0.77% / 1.24%. MiniMax Speech-02 scores 0.99% / 1.90%. ByteDance's own Seed-TTS, the benchmark's namesake, scores 1.12% / 2.25%. S2 does not just edge ahead. It sets a new floor.
| Benchmark | Fish Audio S2 | Best Competitor | Margin |
|---|---|---|---|
| Seed-TTS Eval WER (Chinese) | 0.54% | Qwen3-TTS (0.77%) | 30% lower |
| Seed-TTS Eval WER (English) | 0.99% | MiniMax (0.99%) | Tied / best |
| Audio Turing Test | 0.515 | Seed-TTS (0.417) | +24% |
| EmergentTTS-Eval Win Rate | 81.88% | Next best | Highest overall |
| Instruction Adherence (TAR) | 93.3% | N/A | Fish benchmark |
| Multilingual Best WER | 11/24 langs | Varies | Most wins |
| Multilingual Best SIM | 17/24 langs | Varies | Most wins |
The Audio Turing Test is particularly telling. A score of 0.515 means human evaluators genuinely could not tell whether they were listening to a real human or to S2. The model surpasses Seed-TTS by 24% and MiniMax-Speech by 33% on this metric.
On EmergentTTS-Eval, S2 shines brightest in paralinguistics (91.61% win rate), questions (84.41%), and syntactic complexity (83.39%). These are not easy categories. They test whether the model handles the subtle prosodic demands of real speech.

Production Streaming via SGLang
Here is where the "isomorphic to LLMs" property pays off enormously. Because the Dual-AR architecture looks like a standard autoregressive language model to the serving infrastructure, S2 directly inherits every optimization that SGLang provides for LLM inference.
That means continuous batching, paged KV cache, CUDA graph replay, and RadixAttention-based prefix caching. None of these needed custom implementation. They just work.
The production numbers on a single NVIDIA H200 GPU: a Real-Time Factor of 0.195 (meaning audio generates roughly 5x faster than real-time playback), time-to-first-audio under 100 milliseconds, and throughput of 3,000+ acoustic tokens per second while maintaining RTF below 0.5.
"Because the Dual-AR architecture is structurally isomorphic to standard autoregressive LLMs, S2 directly inherits all LLM-native serving optimizations from SGLang."
For anyone who has struggled to deploy custom TTS models in production, this is a revelation. You do not need to build a bespoke serving stack. You use the same battle-tested infrastructure that powers LLM APIs at scale.
Voice Cloning Without Fine-Tuning
S2 supports zero-shot voice cloning from a short reference sample, typically 10 to 30 seconds. The model extracts the speaker's timbre, speaking style, and emotional tendencies from the reference and applies them to any new text.
No fine-tuning required. No per-voice model training. Just provide a clean audio sample and the model handles the rest. The cloned voice maintains consistency across long passages and different emotional registers.
Multi-Speaker, Multi-Turn
S2 natively supports multiple speakers in a single generation pass. Upload reference audio containing multiple voices, and the model assigns each speaker an identifier token like <|speaker:1|> and <|speaker:2|>. You then control which voice speaks each line.
This eliminates the traditional TTS workflow of generating each speaker separately and stitching audio files together. Dialogue, podcasts, and audiobooks become single-pass operations.
Multi-turn generation extends the context window so that previous audio informs subsequent speech. The model uses earlier output to improve expressiveness and maintain consistency across a conversation. Earlier turns set the emotional and prosodic tone for later ones.
The Competitive Landscape
The open-source TTS space has shifted dramatically over the past year. In 2024, ElevenLabs was the unquestioned quality leader and most open alternatives sounded robotic by comparison. That gap has collapsed.
StyleTTS2 matches ElevenLabs on naturalness. Coqui XTTS matches it on clarity. Bark beats it on raw expressiveness. But none of these projects combine all dimensions the way S2 does: quality, speed, multilingual coverage, emotion control, and production-readiness in a single package.
| System | Type | Voice Cloning | Emotion Control | Languages | Streaming |
|---|---|---|---|---|---|
| Fish Audio S2 | Open source | Zero-shot (10-30s) | Free-form inline tags | ~50 | Sub-100ms TTFA |
| ElevenLabs | Closed API | Fine-tune or instant | Style presets | 29 | Yes |
| Qwen3-TTS | Open source | Zero-shot | Limited | Multi | Yes |
| MiniMax Speech-02 | API | Zero-shot | Tags | Multi | Yes |
| Bark (Suno) | Open source | Speaker prompts | Non-verbal tokens | 13 | No |
| StyleTTS2 | Open source | Reference style | Style transfer | English-focused | Limited |
The cost picture is equally telling. Fish Audio's hosted API runs at roughly $0.05 per minute of generated audio. ElevenLabs charges approximately $0.18. That is a 70% cost reduction. And self-hosting S2 brings the marginal cost down to GPU compute alone.
The Codebase
The repository is written almost entirely in Python (334k lines) with a clean modular structure. The core model code lives in fish_speech/models/, split between text2semantic/ (the Slow AR transformer, LLaMA-based, with LoRA support) and dac/ (the audio codec with RVQ implementation).
Training uses PyTorch Lightning with Hydra for configuration management. The inference engine in fish_speech/inference_engine/ handles reference audio loading, VQ management, and the bridge to SGLang. A Gradio-based WebUI and a standalone API server provide two ways to interact with the model locally.
Dependencies are managed through uv with optional extras for different CUDA versions (cu126, cu128, cu129) and CPU-only mode. Docker support is first-class with both development and production Dockerfiles.
fish-speech/
fish_speech/
models/
text2semantic/ # Slow AR transformer (LLaMA-based)
llama.py # Core model architecture
lora.py # LoRA fine-tuning support
inference.py # Generation logic
dac/ # Audio codec
modded_dac.py # Modified Descript Audio Codec
rvq.py # Residual Vector Quantization
inference_engine/ # SGLang bridge + streaming
tokenizer.py # Text tokenization
train.py # PyTorch Lightning training
tools/
server/ # Production API server
run_webui.py # Gradio interface
vqgan/ # VQ-GAN utilitiesThe License Question
S2 ships under the Fish Audio Research License, not a standard open-source license like MIT or Apache. Research and non-commercial use are free and unrestricted. Commercial use requires a separate written license from Fish Audio.
This is a common pattern for state-of-the-art models. Meta's LLaMA started similarly before eventually loosening terms. For hobbyists, researchers, and evaluators, the license is permissive enough. For businesses, contact business@fish.audio for commercial terms.
Getting Started
Installation is straightforward with uv or pip. The project requires Python 3.10+ and PyTorch 2.8. A single command pulls model weights from HuggingFace and launches the WebUI.
# Install with uv (recommended)
pip install uv
uv pip install fish-speech
# Or clone and install
git clone https://github.com/fishaudio/fish-speech.git
cd fish-speech
uv pip install -e .
# Launch WebUI
python tools/run_webui.pyFor production deployment, the SGLang integration via sglang-omni provides the full serving stack with continuous batching and streaming. Docker compose files handle the orchestration.
What This Means
Fish Audio S2 is a inflection point for TTS. An open-source model now sits at the top of every major benchmark, beating systems built by companies with orders of magnitude more resources. The trajectory is clear: within the next year, the best open-source TTS will consistently outscore closed-source APIs in blind listening tests.
The technical architecture is equally important. By making the model structurally identical to an LLM, Fish Audio unlocked the entire LLM serving ecosystem for free. That is not just an engineering convenience. It means every future improvement to LLM inference infrastructure automatically benefits S2.
For developers, the message is simple. If you are building anything that needs high-quality speech synthesis, self-hostable multilingual TTS, or fine-grained emotional control, Fish Speech S2 is the new starting point.