Heretic: One Command to Uncensor Any LLM
Directional ablation meets Bayesian optimization. Heretic finds and surgically removes refusal behavior from transformer models, fully automatically, while keeping the model's intelligence intact.
- Heretic automates abliteration, the technique of removing a model's "refusal direction" from its weight matrices, using Optuna's TPE optimizer to find parameters that minimize refusals while preserving intelligence.
- It achieves the same refusal suppression as hand-tuned abliterations but at dramatically lower KL divergence, meaning less collateral damage to the model's capabilities.
- The community has published over 1,000 Heretic-processed models on HuggingFace, making it the dominant abliteration tool in the local LLM ecosystem.
- Version 1.2 introduced 4-bit quantization support that cuts VRAM requirements by up to 70%, making abliteration accessible on consumer GPUs.
The Science That Made It Possible
In June 2024, Andy Arditi and colleagues published a finding that rearranged the conversation about AI safety alignment. Their paper, "Refusal in Language Models Is Mediated by a Single Direction," showed that a single vector in a model's activation space controls whether it refuses a request or complies.
That single direction is both necessary and sufficient. Add it to the activations and a helpful model starts refusing everything. Remove it and a censored model becomes compliant. The geometry of refusal is strikingly simple.
This discovery gave birth to abliteration: the technique of mathematically removing the refusal direction from a model's weight matrices. No expensive retraining. No dataset curation. Just linear algebra applied to the right vector.
The Problem with Early Abliteration
The theory was elegant. The practice was messy.
Early tools like abliterator.py, ErisForge, and AutoAbliteration required users to manually select which layers to target, which refusal direction to use, and how aggressively to ablate. Get these wrong and you "lobotomize" the model. It loses coherence, hallucinates more, or just outputs garbage.
Human experts could make it work. Maxime Labonne and huihui-ai published well-regarded abliterated models on HuggingFace. But the process demanded deep understanding of transformer internals and hours of manual experimentation.
Most people who tried abliteration on their own ended up with models that refused less but also thought less. The tradeoff felt unavoidable.
"I was skeptical before, but I just downloaded GPT-OSS 20B Heretic and holy shit. It gives properly formatted long responses to sensitive topics, using the exact uncensored words that you would expect from an uncensored model."
Enter Heretic
Philipp Emanuel Weidmann released Heretic in September 2025. Its premise: if abliteration has tunable parameters, let a machine find the best ones.
The install is a pip command. The usage is a single line.
pip install -U heretic-llm
heretic Qwen/Qwen3-4B-Instruct-2507That is the entire workflow. Heretic downloads the model, benchmarks your hardware, runs 200 optimization trials, and produces a decensored model. No configuration file required. No transformer expertise needed.
The tool hit #1 Repository of the Day on GitHub Trending and climbed to over 15,000 stars within months. The community response was immediate and enthusiastic.
How It Actually Works
Heretic implements a parametrized variant of directional ablation. The process has two phases: computing refusal directions, then optimizing how to apply them.
Phase 1: Finding the Refusal Direction
Heretic loads two datasets from HuggingFace: one of harmless prompts (normal questions) and one of harmful prompts (questions that trigger refusals). It runs both through the target model and captures the hidden states at the first output token for every transformer layer.
For each layer, it computes the refusal direction as the difference between the mean harmful residual and the mean harmless residual. This vector points in the direction the model uses to encode "I should refuse this."
Phase 2: Optimizing the Ablation
This is where Heretic diverges from prior tools. Instead of applying a fixed ablation, it treats the process as an optimization problem with several parameters.
The direction_index controls which refusal direction to use. Uniquely, this can be a float. For non-integer values, Heretic interpolates between two adjacent layer directions, unlocking directions that no single layer produces on its own.
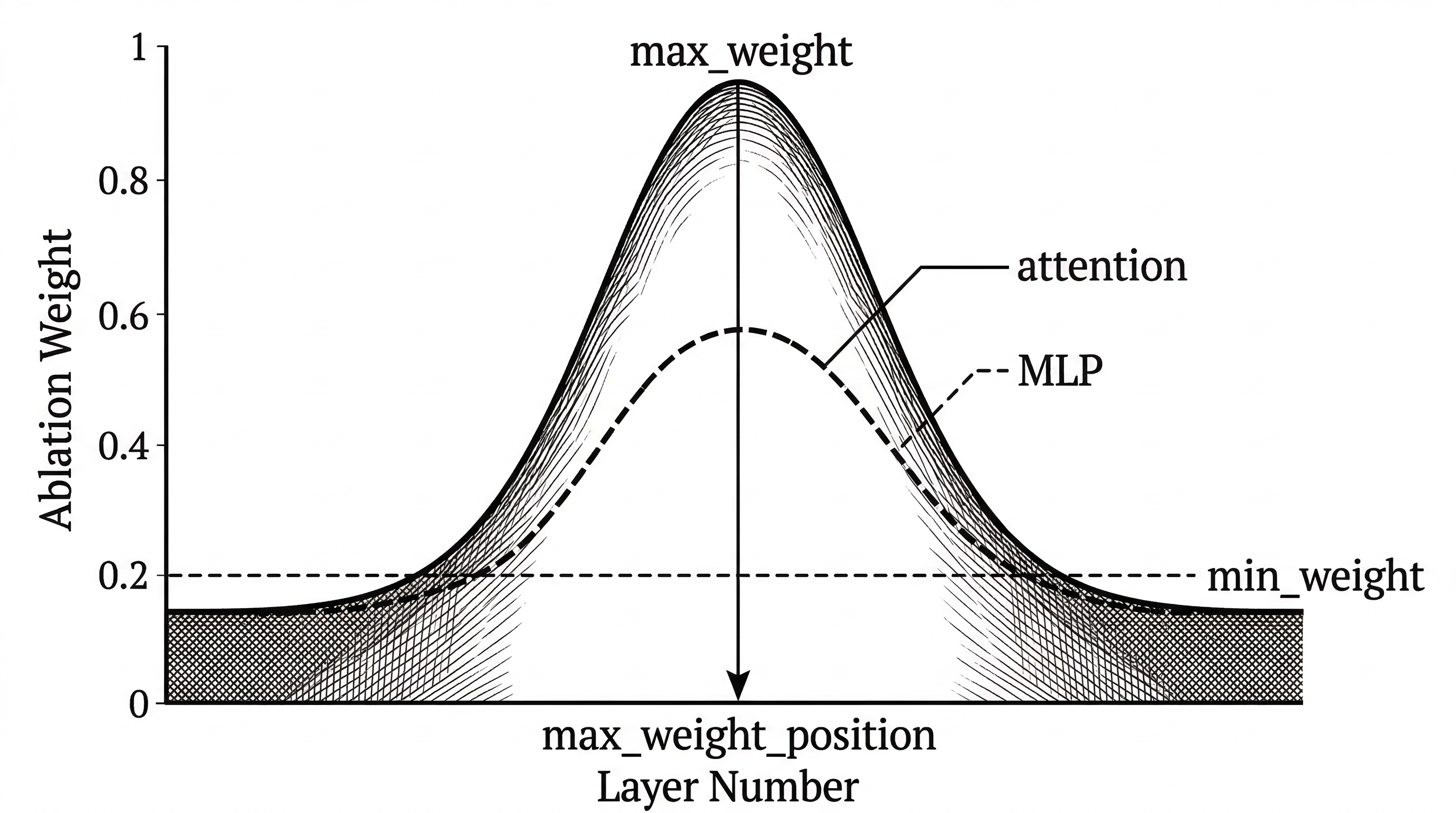
The weight kernel controls how much ablation each layer receives. Four parameters define its shape: max_weight, max_weight_position, min_weight, and min_weight_distance. This creates a smooth curve over layers rather than a binary on/off switch. Early and late layers can receive different amounts of intervention.
Crucially, attention and MLP components get separate parameters. Heretic's author found that MLP interventions tend to be more damaging to model intelligence than attention interventions. Separate tuning lets the optimizer be aggressive on attention while gentle on MLPs.
The Optimization Loop
Optuna's Tree-structured Parzen Estimator (TPE) drives the search. Each trial proposes a set of ablation parameters, applies them to the model, and measures two things: how many harmful prompts still produce refusals, and the KL divergence of the ablated model from the original on harmless prompts.
The first metric measures compliance. The second measures intelligence preservation. Heretic co-minimizes both, seeking the sweet spot where the model stops refusing but keeps thinking clearly.
Of the 200 default trials, the first 60 use random sampling to explore the parameter space broadly. The remaining 140 use informed sampling to exploit promising regions. Checkpoints save progress so you can resume interrupted runs.
The Numbers
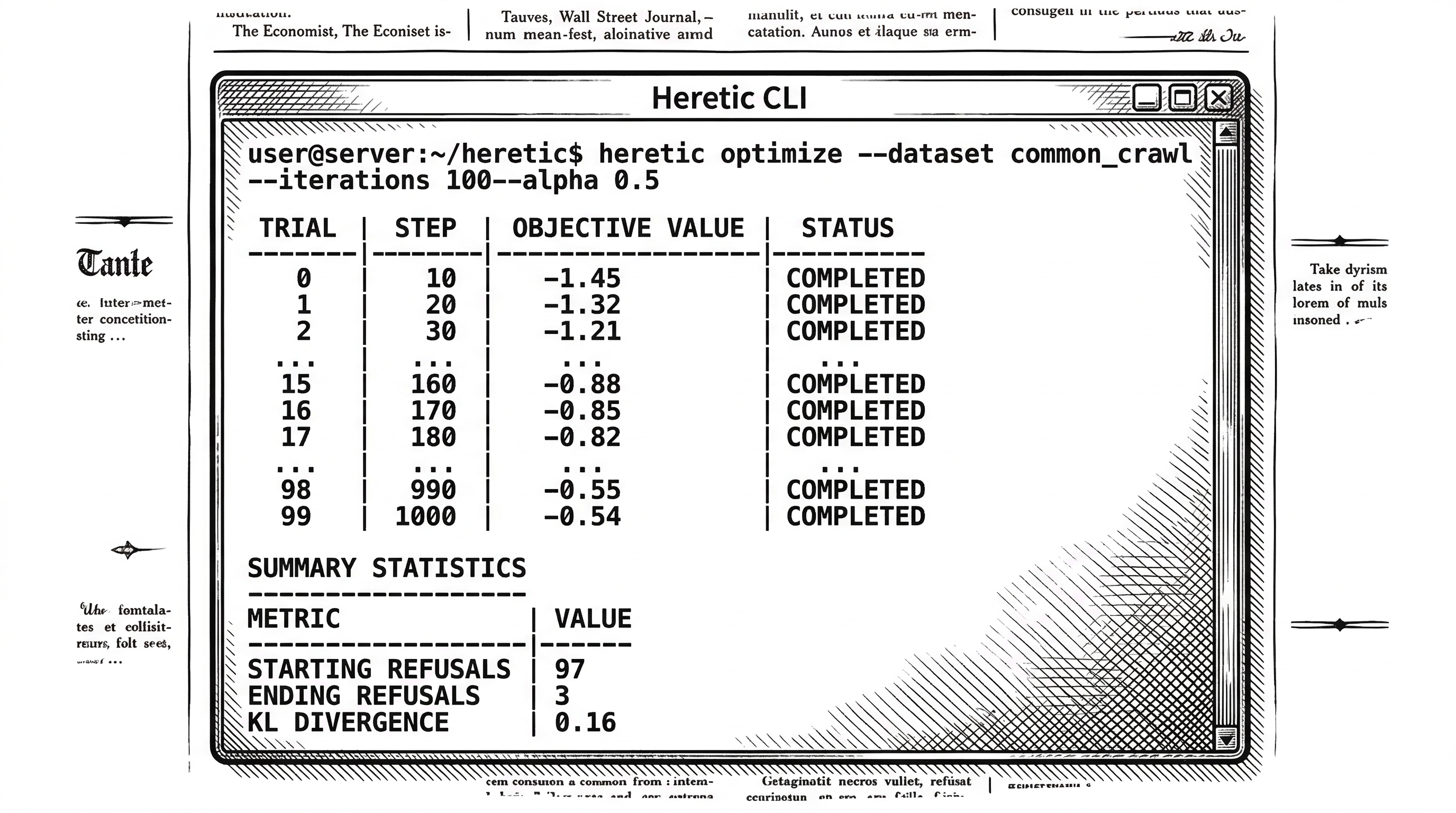
Heretic's README includes a comparison that tells the story clearly. On Gemma 3 12B Instruct, three different approaches all reduce refusals from 97/100 to 3/100. The difference is in the damage.
| Model | Refusals (of 100) | KL Divergence |
|---|---|---|
| Original (google/gemma-3-12b-it) | 97 | 0 (baseline) |
| mlabonne/gemma-3-12b-it-abliterated-v2 | 3 | 1.04 |
| huihui-ai/gemma-3-12b-it-abliterated | 3 | 0.45 |
| Heretic (p-e-w/gemma-3-12b-it-heretic) | 3 | 0.16 |
A KL divergence of 0.16 versus 1.04 is not incremental. It is a 6.5x reduction in distribution shift. The Heretic model is measurably closer to the original in every way except its willingness to refuse. And it found those parameters without a human touching a single setting.
An academic paper from December 2025 (Comparative Analysis of LLM Abliteration Methods, arXiv:2512.13655) tested Heretic across sixteen instruction-tuned models from 7B to 14B parameters. Heretic was the only tool that successfully processed all sixteen. DECCP managed eleven, ErisForge nine, and FailSpy five.
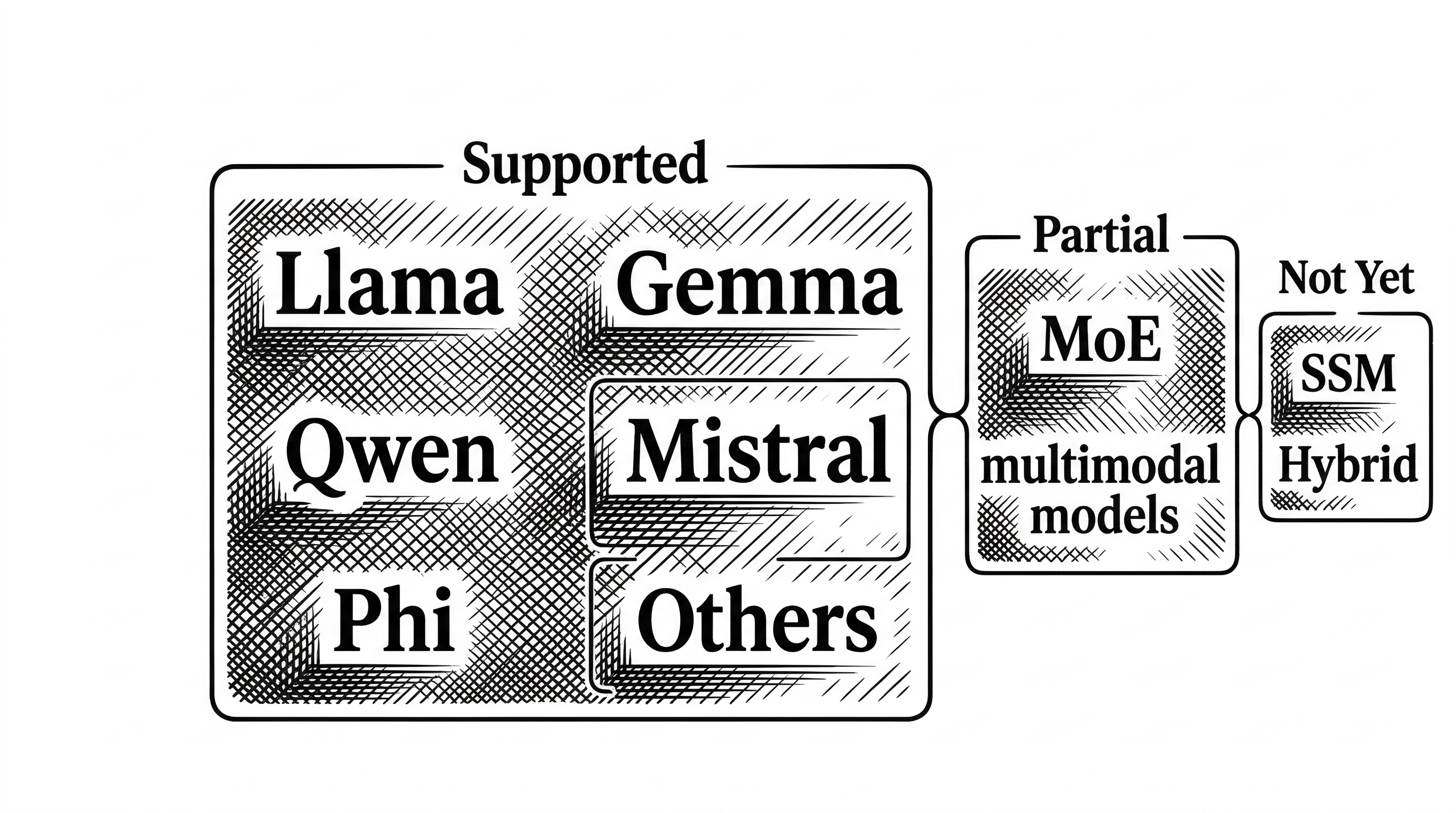
Architecture Compatibility
Heretic works with most dense transformer models. That includes the major families: Llama, Gemma, Qwen, Mistral, Phi, and many others. It supports several mixture-of-experts (MoE) architectures too.
Multimodal models are partially supported. If the model uses a standard transformer backbone for its language component, Heretic can ablate it. The vision encoder stays untouched.
What it cannot handle yet: state-space models (SSMs), hybrid architectures, models with inhomogeneous layers, and certain novel attention systems. The tool detects unsupported architectures and fails gracefully rather than producing broken output.
The 1.2 Release: VRAM for Everyone
Heretic 1.2 landed in early 2026 with a feature the community had been requesting loudly: quantization support. By setting quantization = "bnb_4bit", users can load models in 4-bit precision via bitsandbytes. This cuts VRAM usage by up to 70%.
A model that previously required a 48GB A6000 can now be processed on a 16GB consumer card. This moved abliteration from a datacenter-grade hobby to something anyone with a gaming GPU can do on a Saturday afternoon.
The release also introduced Magnitude-Preserving Orthogonal Ablation (MPOA), a technique that preserves the original row magnitudes of the weight matrices after ablation. This reduces a subtle source of quality degradation that affected earlier versions.
Research Features
Heretic is not just a production tool. It includes research capabilities that make it useful for interpretability work.
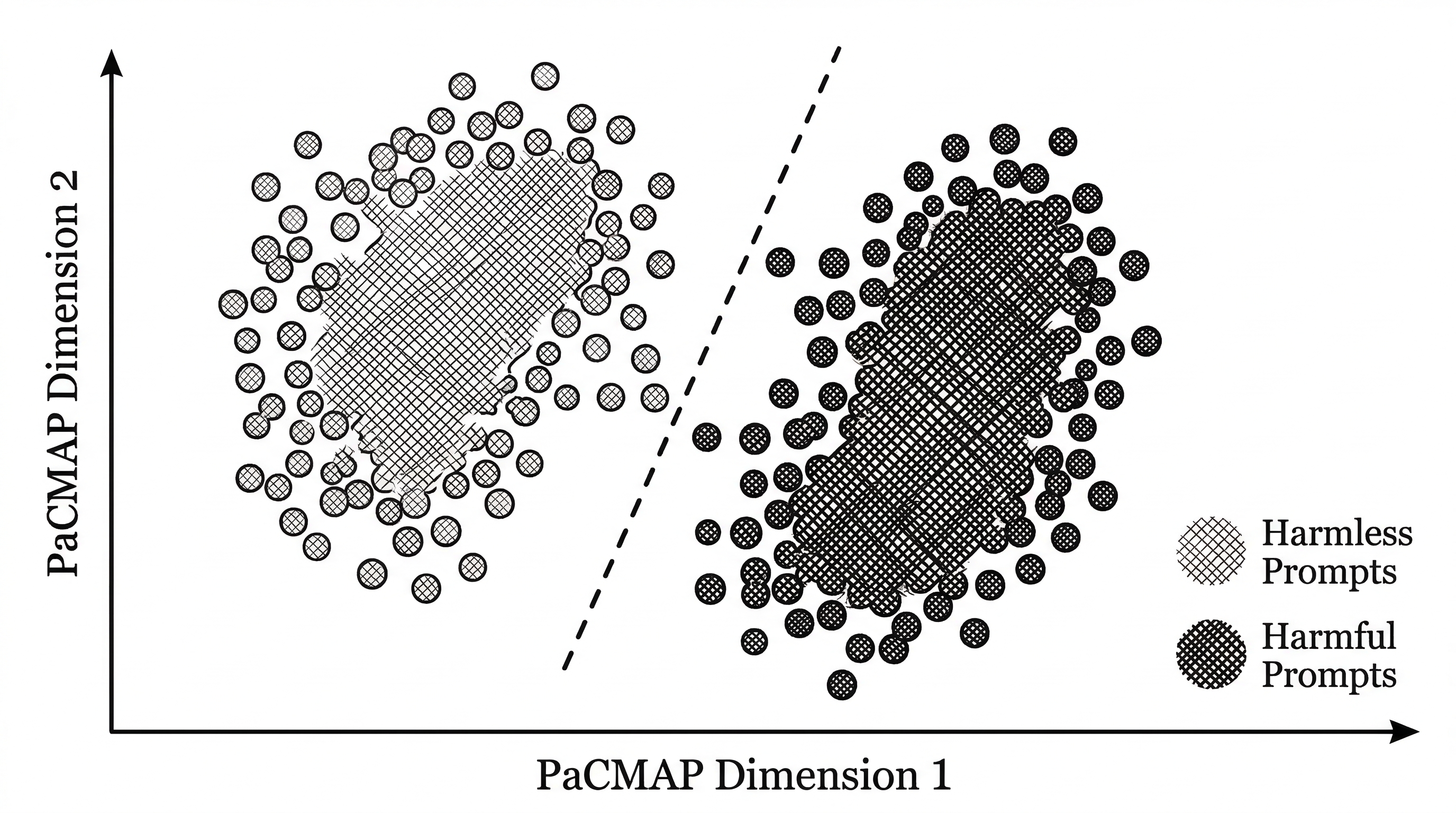
The --plot-residuals flag generates PaCMAP projections of residual vectors, showing how harmful and harmless prompts separate in each layer's activation space. The output is a series of scatter plots plus an animated GIF showing the transformation across layers.
The --print-residual-geometry flag dumps a detailed table of cosine similarities, L2 norms, and silhouette coefficients for the residual clusters at each layer. This quantitative view helps researchers understand where and how strongly a model encodes refusal behavior.
These features turn Heretic into a diagnostic tool. Even if you never intend to decensor a model, the residual analysis can reveal how safety alignment manifests in the geometry of a model's internal representations.
The Competitive Landscape
Heretic is not the only abliteration tool, but it has become the dominant one. Here is how it stacks up.
| Tool | Approach | Automation | Architecture Coverage |
|---|---|---|---|
| Heretic | Bayesian-optimized directional ablation | Fully automatic | 16/16 tested models |
| DECCP | Quantized single-pass ablation | Semi-automatic | 11/16 tested models |
| ErisForge | Runtime wrappers | Manual configuration | 9/16 tested models |
| FailSpy | Activation hooks | Manual configuration | 5/16 tested models |
| abliterate.cpp | llama.cpp-based ablation | Manual configuration | Limited |
The tradeoff is speed. Single-pass methods like DECCP and ErisForge are faster because they skip optimization entirely. They also show slightly less capability degradation on certain benchmarks. But they require more manual tuning and support fewer architectures.
For most users, especially those without deep transformer knowledge, Heretic's fully automatic approach and broad compatibility make it the practical choice. The optimization loop takes about 45 minutes on an RTX 3090 for an 8B model. That is a small price for zero configuration.
The Author
Philipp Emanuel Weidmann (p-e-w on GitHub) has a track record of shipping polished developer tools. His earlier projects include Hegemon, a modular system monitor written in Rust, and Savage, a computer algebra system. More recently he built Waidrin, a next-generation AI roleplay system.
Heretic was written from scratch. The README explicitly notes that it does not reuse code from any prior abliteration tool. The codebase is pure Python, roughly 109k characters across seven source files, using modern dependencies like Transformers 5.x, Accelerate, PEFT, and Optuna.
The project is licensed under AGPL-3.0, which means derivative works must also be open source. This is an intentional choice: any company that builds on Heretic must contribute improvements back to the community.
"Heretic GPT 20b seems to be the best uncensored model I have tried yet. It doesn't destroy a the model's intelligence and it is answering prompts normally would be rejected by the base model."
Configuration for Power Users
While Heretic works out of the box, the config.default.toml file exposes over 30 tunable parameters. Power users can control batch sizes, response length, quantization settings, the number of optimization trials, custom refusal markers, and the datasets used for both direction computation and evaluation.
The config.noslop.toml variant ships with an alternative configuration optimized for reducing "slop" (generic, overconfident AI-sounding language) in addition to removing refusals. This targets a different annoyance that many local LLM users care about.
Refusal detection uses a string-matching approach with a configurable list of markers like "sorry," "I cannot," "as an AI," and "inappropriate." This is simple but effective. The marker list can be customized for models that refuse in unusual ways or in non-English languages.
What Happens After Ablation
When Heretic finishes its optimization run, it presents an interactive menu. You can save the model locally in standard HuggingFace format. You can upload it directly to HuggingFace Hub. Or you can chat with it right there in the terminal to verify it works before committing.
The output is a standard model that works with any inference framework: vLLM, llama.cpp (after conversion), TGI, or plain Transformers. No special runtime required. The ablation modifies the weights permanently.
When full row normalization is enabled, Heretic produces a LoRA adapter instead of modifying weights directly. This keeps the output files smaller and can help preserve model quality through the approximation.
The Bigger Picture
Heretic exists at the intersection of two forces. On one side, model providers are adding increasingly aggressive safety filters. On the other, local LLM users want models that respond to any prompt without judgment.
The tool does not take a political stance in its documentation. It presents itself as a research and practical utility. The README describes its function matter-of-factly: "removes censorship (aka 'safety alignment') from transformer-based language models."
The community has spoken with their stars and their models. Over 1,000 Heretic-processed models on HuggingFace represent more than a third of all publicly available abliterated models. That adoption tells the story of a tool that met a real need with a genuinely better solution.
Whether you view this as a win for user autonomy or a concern for AI safety depends on your perspective. What is not debatable is the engineering. Heretic turned a fragile manual process into a reliable automated one, and it did so with clean code, rigorous optimization, and broad compatibility.