Hindsight: The Agent Memory System That Learns, Not Just Remembers
Vectorize's open-source memory layer uses biomimetic data structures to hit 91.4% on LongMemEval. Two lines of code give your agent world facts, experiences, and mental models that evolve over time.
- Hindsight achieves 91.4% on the LongMemEval benchmark, verified by Virginia Tech and The Washington Post, outperforming every other agent memory system tested.
- Its biomimetic architecture splits memory into world facts, experiences, and mental models, then synthesizes them through a reflect operation that lets agents form new beliefs.
- Four parallel retrieval strategies (semantic, BM25, graph traversal, temporal) merged via reciprocal rank fusion deliver accuracy that simple vector search cannot match.
- An MIT license, Docker-first deployment, and two-line LLM wrapper integration make Hindsight practical for both startups and Fortune 500 production systems.
The Memory Problem Nobody Solved
Every agent framework promises memory. Most of them mean "we store your chat history in a vector database and do similarity search." That works fine for recalling what someone said three turns ago. It falls apart when an agent needs to understand that Alice got promoted last June, connect that to her earlier career aspirations, and reason about what she might need next.
RAG retrieves documents. Knowledge graphs store relationships. Neither one learns. The agent stays as naive on day 100 as it was on day one, dutifully fetching context without ever building understanding.
"Most agent memory systems focus on recalling conversation history. Hindsight is focused on making agents that learn, not just remember."
Vectorize, a seed-stage startup led by former Google Cloud solution architect Chris Latimer, launched Hindsight in late 2025 to fix this. The project hit 4,600+ stars, earned an arXiv paper, and was independently benchmarked by Virginia Tech's Sanghani Center for AI. It is now running in production at Fortune 500 companies.
Biomimetic Memory: World, Experiences, Mental Models
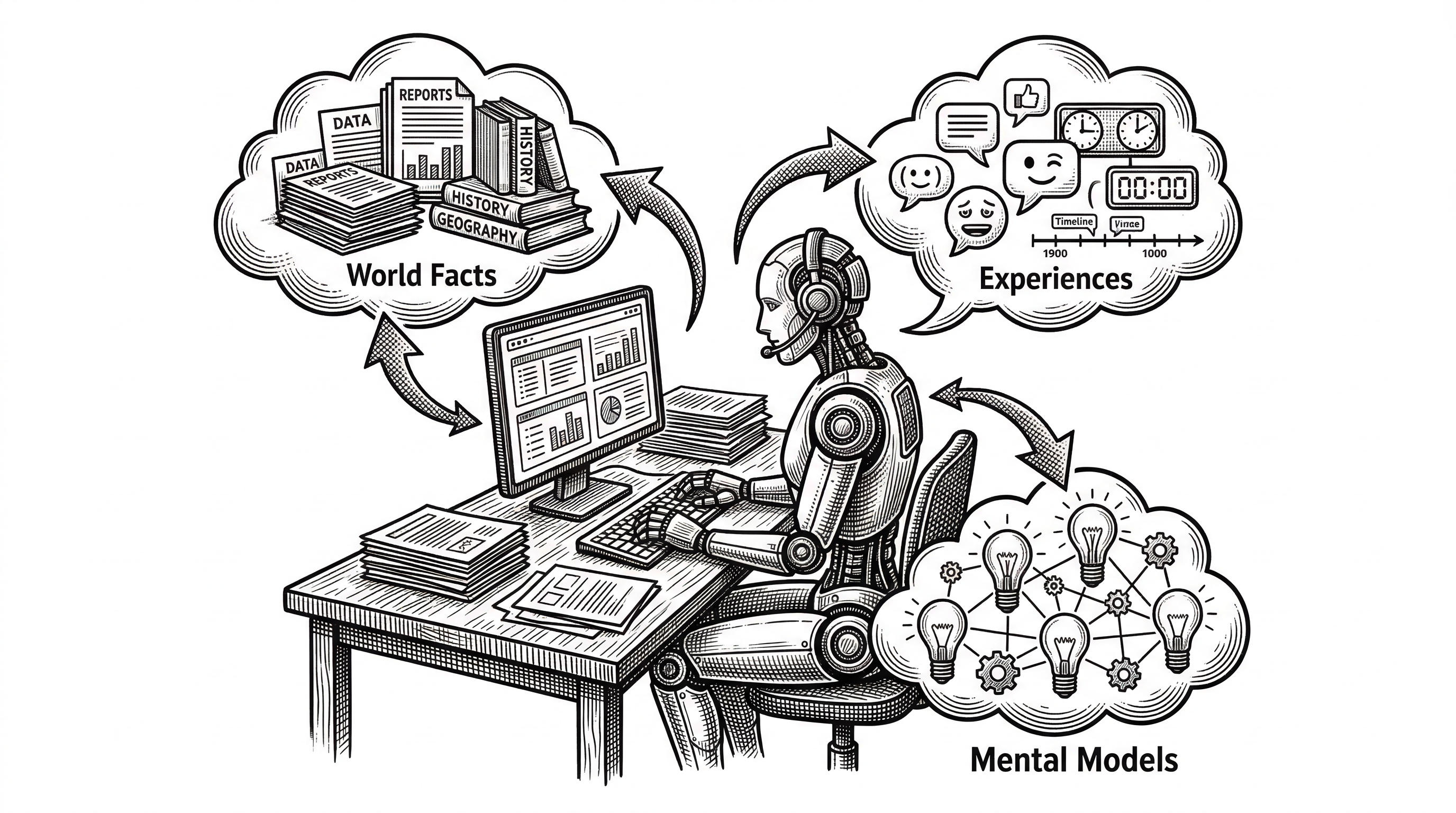
The core insight behind Hindsight is that human memory is not a flat search index. Humans maintain separate but interconnected systems for factual knowledge, personal experiences, and learned mental models. Hindsight mirrors this with three memory types.
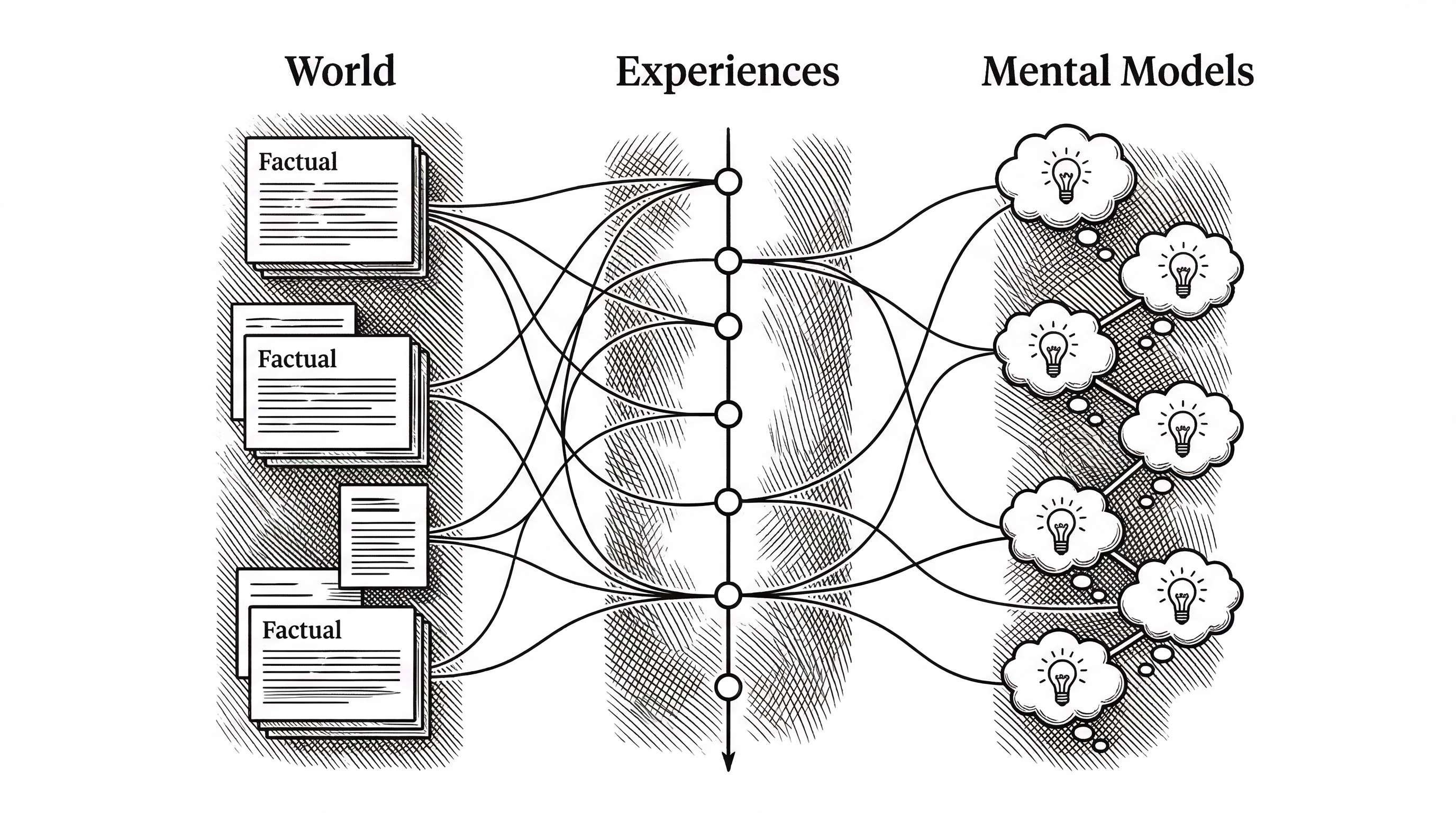
World facts are things the agent knows about reality. "The stove gets hot." "Alice works at Google." These are stored as entities, relationships, and time series with dense and sparse vector representations.
Experiences are the agent's own interactions. "I touched the stove and it hurt." "I asked Alice about her job and she mentioned a promotion." These are first-person events, timestamped and linked to the entities they reference.
Mental models are the interesting part. These are not raw data at all. They are synthesized beliefs formed by reflecting on world facts and experiences together. "Alice is ambitious and values career growth" is something no single input ever stated. The agent figured it out.
Three Verbs: Retain, Recall, Reflect
Hindsight exposes exactly three operations. The naming is deliberate: these are cognitive verbs, not database CRUD.
Retain
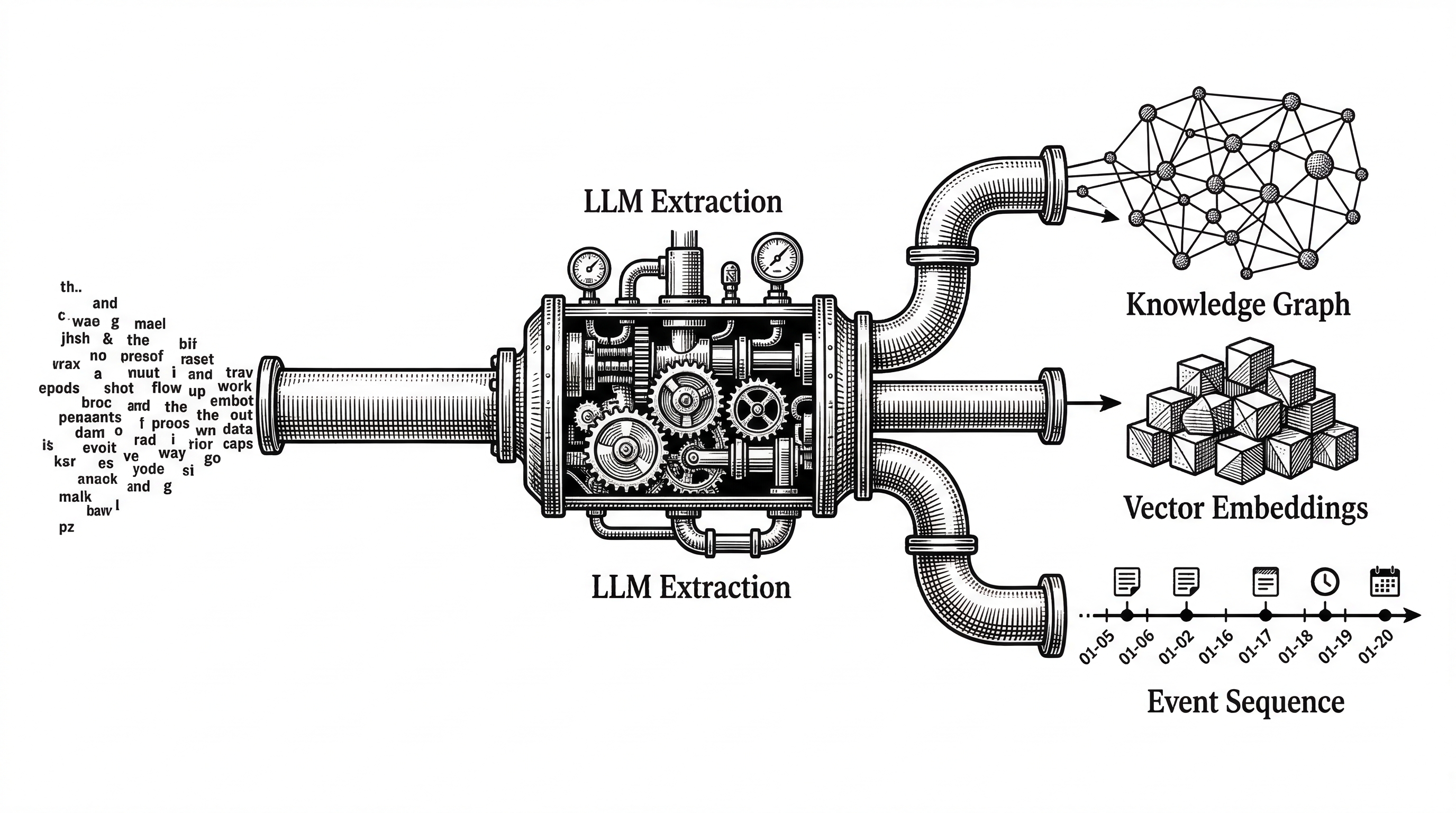
Push information into Hindsight. Behind the scenes, an LLM extracts entities, relationships, temporal markers, and key facts. These pass through a normalization pipeline that creates canonical representations across all memory types.
from hindsight_client import Hindsight
client = Hindsight(base_url="http://localhost:8888")
client.retain(
bank_id="my-bank",
content="Alice got promoted to senior engineer at Google",
context="career update",
timestamp="2025-06-15T10:00:00Z"
)One call. The system handles entity extraction, deduplication, vector indexing, graph updates, and temporal placement. The developer never touches any of it.
Recall
Retrieve memories. This is where Hindsight's architecture pays off. Instead of running a single vector similarity search, recall fires four retrieval strategies in parallel.
Semantic search finds conceptually similar memories using dense vectors. BM25 keyword matching catches exact terms that embedding models might miss. Graph traversal follows entity and causal links to find related facts. Temporal filtering handles time-bound queries like "what happened last month."
# Simple recall
results = client.recall(bank_id="my-bank", query="What does Alice do?")
# Temporal recall
results = client.recall(bank_id="my-bank", query="What happened in June?")Results from all four strategies are merged using reciprocal rank fusion, then reranked by a cross-encoder model. The final output is trimmed to fit token limits. This is the TEMPR pipeline: Temporal Entity Memory Priming Retrieval.
Reflect
This is the operation that separates Hindsight from everything else. Reflect does not retrieve stored memories. It reasons over them to produce new understanding.
client.reflect(bank_id="my-bank", query="What should I know about Alice?")An AI project manager can reflect on what risks need mitigation. A sales agent can reflect on why certain outreach messages worked while others did not. A support agent can identify gaps in product documentation by reflecting on recurring questions.
The reflect operation creates new mental models. These persist in the memory bank and become available to future recall operations. The agent's understanding compounds over time.
The Benchmark That Matters
LongMemEval is the standard test for agent memory systems. It evaluates how well a system handles long-running conversational scenarios spanning many sessions and hundreds of thousands of tokens. It is the closest thing the field has to an objective measure of memory quality.
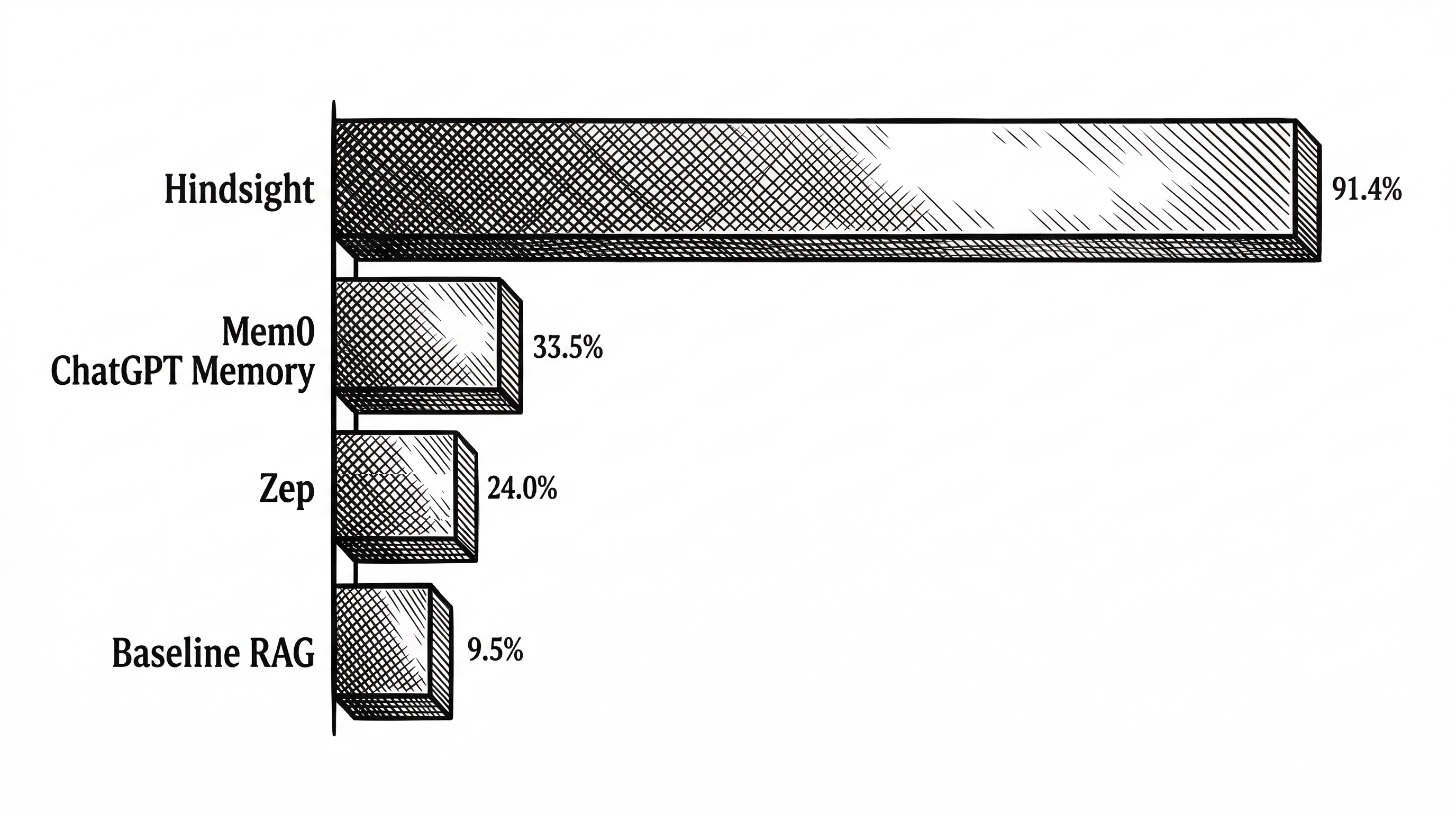
Hindsight scored 91.4%. That result was independently reproduced by researchers at Virginia Tech's Sanghani Center for AI and Data Analytics and by The Washington Post. Other scores in the benchmark are self-reported by vendors.
The gap matters because it shows what biomimetic memory organization plus multi-strategy retrieval can do versus simpler approaches. Vector search alone caps out well below this. Knowledge graphs alone cap out well below this. The combination, with reflect on top, pushes through.
"Hindsight eliminates the shortcomings of alternative techniques such as RAG and knowledge graph and delivers state-of-the-art performance on long term memory tasks."
Two Lines of Code to Memory
The fastest integration path is the LLM Wrapper. You swap your existing LLM client for Hindsight's wrapper and memories are stored and retrieved automatically as you make LLM calls. Two lines. No schema changes, no new APIs to learn.
For developers who want finer control, the Python and Node.js SDKs expose retain, recall, and reflect directly. There is also a REST API and a CLI for scripting.
# Docker: one command to run the full stack
export OPENAI_API_KEY=sk-xxx
docker run --rm -it --pull always -p 8888:8888 -p 9999:9999 \
-e HINDSIGHT_API_LLM_API_KEY=$OPENAI_API_KEY \
-v $HOME/.hindsight-docker:/home/hindsight/.pg0 \
ghcr.io/vectorize-io/hindsight:latestThat gives you the API on port 8888 and a web UI on port 9999. The embedded Python mode skips Docker entirely and runs the full server in-process. For teams that need complete data privacy, Hindsight runs locally with Ollama, no API keys required, no data leaving the machine.
What is Actually Inside the Repo
The repository is substantial. Python is the primary language at roughly 5.7 million bytes, with significant TypeScript (the control plane UI), Rust (the embedding engine), and Shell scripts. The structure reveals careful separation of concerns.
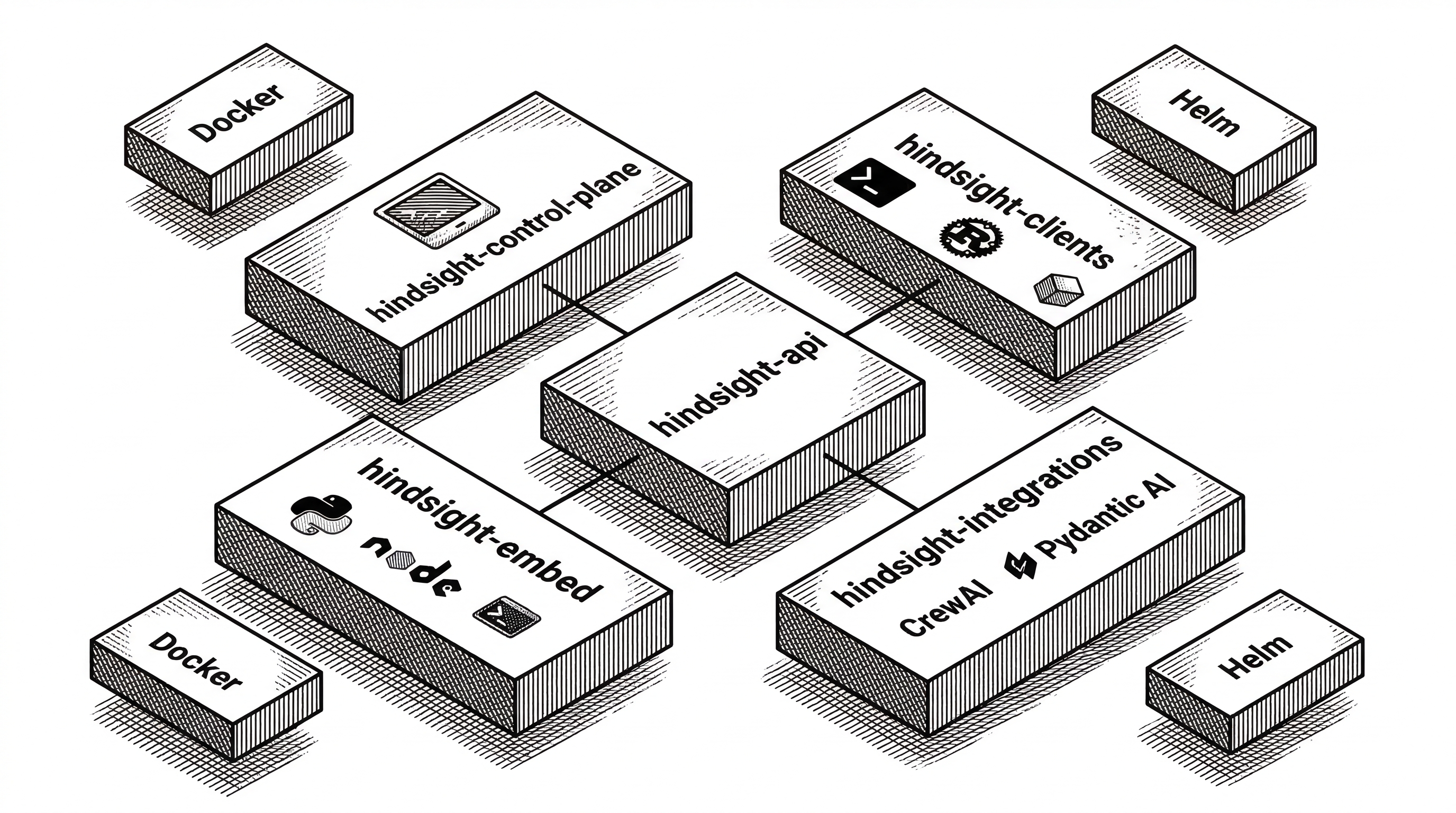
hindsight-api and hindsight-api-slim are the core server. The slim variant strips optional dependencies for lighter deployments. hindsight-control-plane is a Next.js dashboard built with Tailwind for managing memory banks and inspecting stored memories.
hindsight-embed is a Rust-based embedding engine, explaining the 292k bytes of Rust in the language breakdown. This handles the dense vector generation that powers semantic retrieval.
hindsight-integrations provides first-class support for the Vercel AI SDK, CrewAI, and Pydantic AI. These are not wrappers; they are tested packages with their own pyproject.toml files and test suites.
hindsight-cli gives terminal-first developers direct access to all operations. The docker and helm directories handle container and Kubernetes deployments respectively.
The Competitive Landscape
Agent memory is a crowded space in 2026. Hindsight competes with at least four established players, each with a different philosophy.
| System | Approach | Strengths | Limitations |
|---|---|---|---|
| Hindsight | Biomimetic (World + Experiences + Mental Models) | 91.4% LongMemEval, reflect operation, MIT license | Requires LLM for retain; newer project |
| Mem0 | Memory layer with graph extraction | Fast managed service, broad adoption | Graph features require $249/mo Pro tier |
| Zep | Temporal knowledge graph | Strong time-awareness, structured business data | More complex architecture to configure |
| Letta | Self-editing agent memory | Agents manage their own context window | Comes with its own agent runtime; less flexible |
| LangMem | LangGraph integration | Tight LangChain ecosystem fit | Requires LangGraph; limited outside that ecosystem |
Hindsight's differentiation is the reflect operation. Mem0, Zep, and Letta all store and retrieve. None of them synthesize new understanding from existing memories. That gap is the difference between an agent that remembers and one that learns.
The benchmark numbers back this up. Hindsight's 91.4% was independently verified. Other vendors self-report their scores. The methodological difference matters when choosing infrastructure for production.
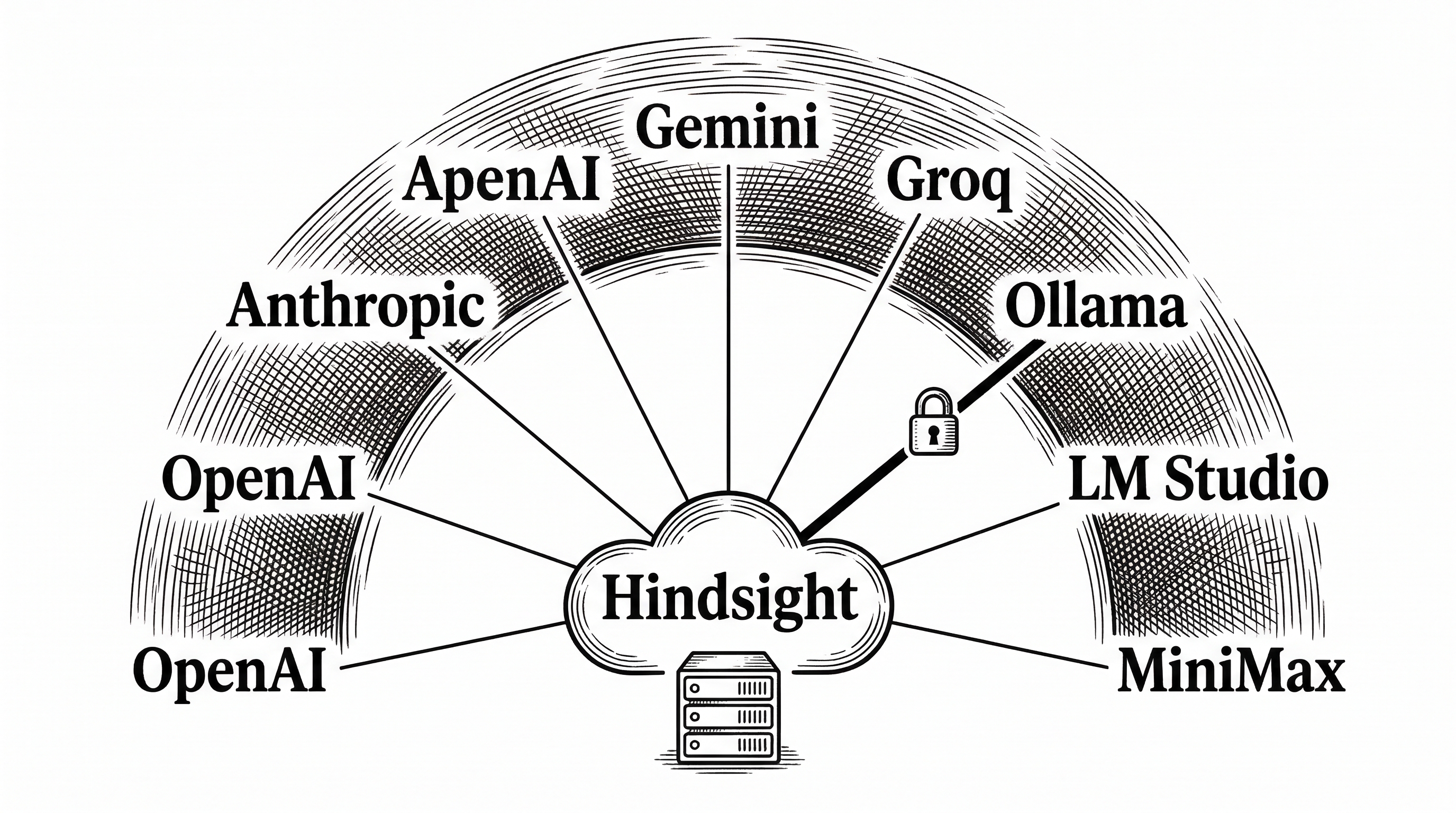
LLM Provider Flexibility
Hindsight is not locked to OpenAI. The HINDSIGHT_API_LLM_PROVIDER environment variable accepts seven options: OpenAI, Anthropic, Gemini, Groq, Ollama, LM Studio, and MiniMax. This is not a superficial integration. Each provider has documented model support and tested configurations.
The Ollama path deserves special mention. It enables a fully air-gapped deployment: local LLM, local embeddings, local PostgreSQL. No API keys. No cloud costs. No data leaving the machine. For regulated industries and privacy-sensitive applications, this is the on-ramp.
MCP: Memory for Any Agent
In March 2026, Vectorize shipped MCP (Model Context Protocol) support. This means any MCP-compatible agent can connect to Hindsight and get persistent, structured long-term memory without writing integration code.
The MCP server exposes retain, recall, and reflect as standard tool calls. Claude, Cursor, and other AI coding assistants can use it directly. Vectorize even ships a documentation skill that coding agents can install with a single npx command to get inline access to Hindsight's docs while coding.
# Install the Hindsight docs skill for AI coding assistants
npx skills add https://github.com/vectorize-io/hindsight --skill hindsight-docsThe Paper: Hindsight is 20/20
The arXiv paper (2512.12818) lays out the theoretical foundation. The title, "Hindsight is 20/20: Building Agent Memory that Retains, Recalls, and Reflects," describes the TEMPR retrieval algorithm in detail.
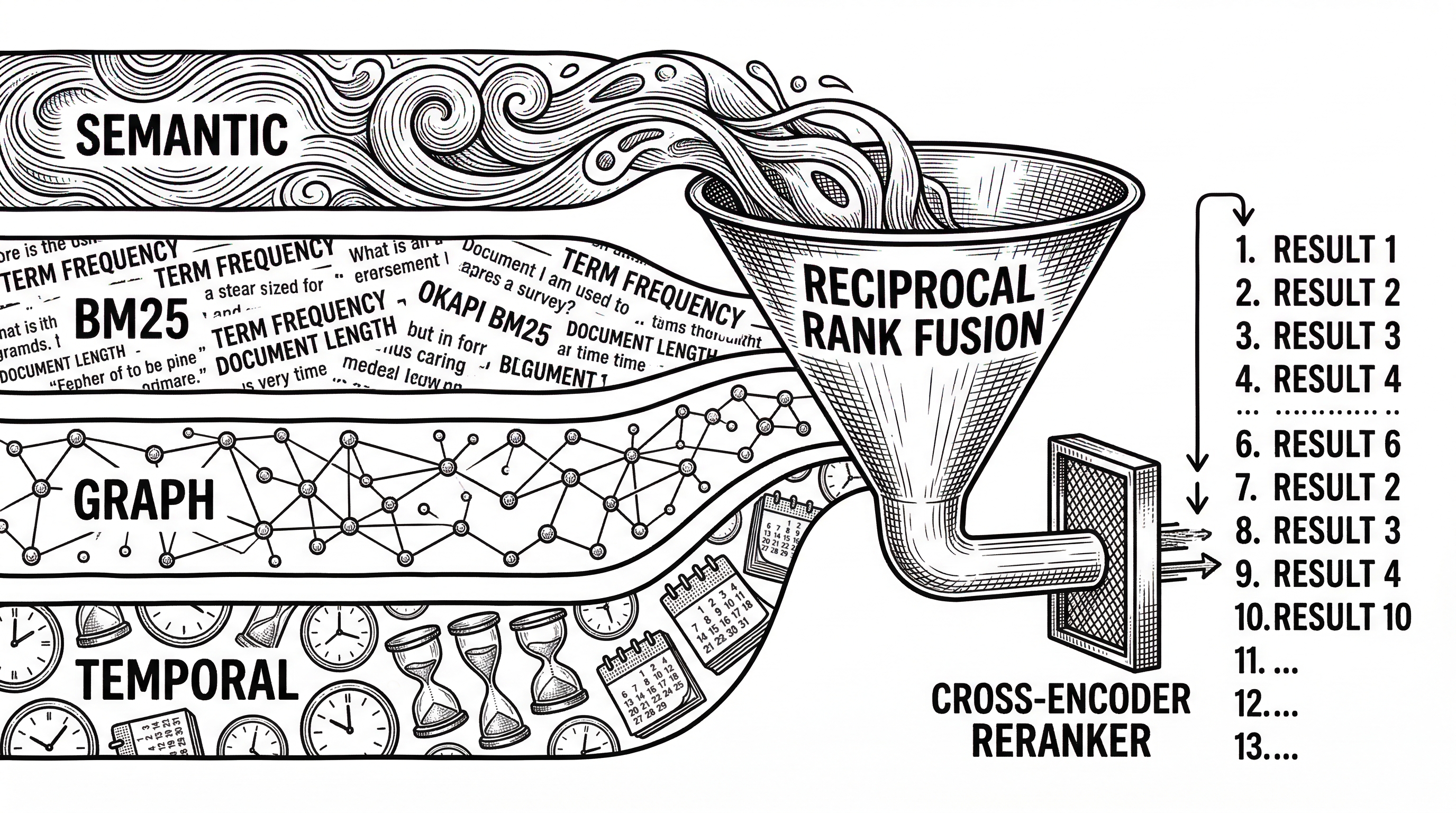
TEMPR runs four searches in parallel. Semantic similarity via dense vectors catches conceptual matches. BM25 keyword matching catches exact terms that embeddings might smooth over. Graph traversal follows entity relationships and causal chains. Temporal filtering handles time-scoped queries.
The four result sets are merged using reciprocal rank fusion, a technique that combines ranked lists without needing comparable scores. A cross-encoder reranker then reorders the final list for precision. This is not a simple union. Each strategy compensates for the others' blind spots.
Per-User Memory in Practice
One of the cleaner use cases is per-user personalization. A chatbot retains memories about each user in separate memory banks, filtered by metadata. When the user returns days later, the agent recalls their preferences, history, and context without the user repeating themselves.
This is table stakes for consumer AI products but surprisingly hard to implement well. Most systems either dump everything into one context window (expensive, slow) or rely on keyword search (brittle, misses nuance). Hindsight's metadata filtering on retain combined with multi-strategy recall on the other end handles both problems.
Where It Gets Interesting: Autonomous Agents
The real target is not chatbots. It is autonomous agents that perform open-ended work. An AI employee that handles support tickets, learns which solutions work, adapts its approach based on feedback, and improves over months.
This requires all three memory types working together. World facts store product knowledge. Experiences track the agent's own interactions and outcomes. Mental models capture learned heuristics: "customers asking about billing usually need the self-service portal link" is something the agent synthesizes, not something anyone explicitly taught it.
The reflect operation is what makes this loop close. Without it, the agent accumulates data but never distills it into wisdom. With it, the agent's performance compounds. That is the central bet Vectorize is making: agents that learn will outperform agents that merely remember.
What to Watch
Hindsight is version 0.4.18 as of this writing. The project is moving fast, with commits landing daily and the repo last pushed today. The cloud offering (Hindsight Cloud) provides a managed version for teams that do not want to self-host.
The competitive dynamics in agent memory are intensifying. Mem0 is pushing graph capabilities. Zep is deepening temporal reasoning. Letta is building a full agent runtime. Hindsight's angle, the reflect operation and biomimetic memory organization, is the most distinctive technical bet in the space.
If the LongMemEval numbers hold as benchmarks get harder and use cases get more demanding, Hindsight could become the standard memory layer for the next generation of autonomous AI agents. The foundation is solid. The question is whether Vectorize can scale both the technology and the company fast enough to hold the lead.