learn-claude-code: The 31k-Star Repo That Says Your Agent Framework Is a Lie
shareAI-lab's open-source curriculum reverse-engineers Claude Code's architecture and rebuilds it from scratch in 12 sessions. The punchline: the entire secret fits in a while loop.
- learn-claude-code proves that a production-grade AI coding agent is a while loop, a tool dispatch map, and a model that decides when to stop, not a framework with a graph engine and a hundred abstractions.
- The repo's core thesis, "the model IS the agent," reframes the developer's job from building intelligence to building the harness (tools, knowledge, context, permissions) that lets intelligence express itself.
- Twelve progressive Python sessions take you from a 90-line single-tool agent to autonomous multi-agent teams with git worktree isolation, context compression, and async mailboxes.
- With 31,000+ stars and 5,000+ forks in under a year, it has become the de facto open-source curriculum for understanding how Claude Code actually works under the hood.
The Most Dangerous Idea in AI Engineering
The model is the agent. Not the framework. Not the prompt chain. Not the drag-and-drop workflow builder. That is the thesis of learn-claude-code, and it is a thesis that threatens every "AI agent platform" charging you a subscription.
shareAI-lab's repository does not teach you how to use a library. It teaches you why you do not need one. Starting from a blank Python file and the Anthropic API, the curriculum builds a fully functional coding agent in 12 sessions. Each session adds exactly one mechanism. Each mechanism is explained in context, with ASCII diagrams in the source comments and a companion web interface at learn.shareai.run.
The project hit 31,000 GitHub stars in under a year. It has been forked over 5,000 times. And its README opens with a history lesson on what "agent" has always meant in AI: a trained model that perceives, reasons, and acts. Not a Rube Goldberg machine of if-else branches with an LLM wedged in as a text-completion node.
Session 01: Ninety Lines That Change Everything
The first session is the whole point. It fits on a single screen. A system prompt tells the model it is a coding agent. One tool definition gives it bash access. And the agent loop is this:
def agent_loop(messages):
while True:
response = client.messages.create(
model=MODEL, system=SYSTEM,
messages=messages, tools=TOOLS,
)
messages.append({"role": "assistant", "content": response.content})
if response.stop_reason != "tool_use":
return
results = []
for block in response.content:
if block.type == "tool_use":
output = run_bash(block.input["command"])
results.append({"type": "tool_result",
"tool_use_id": block.id, "content": output})
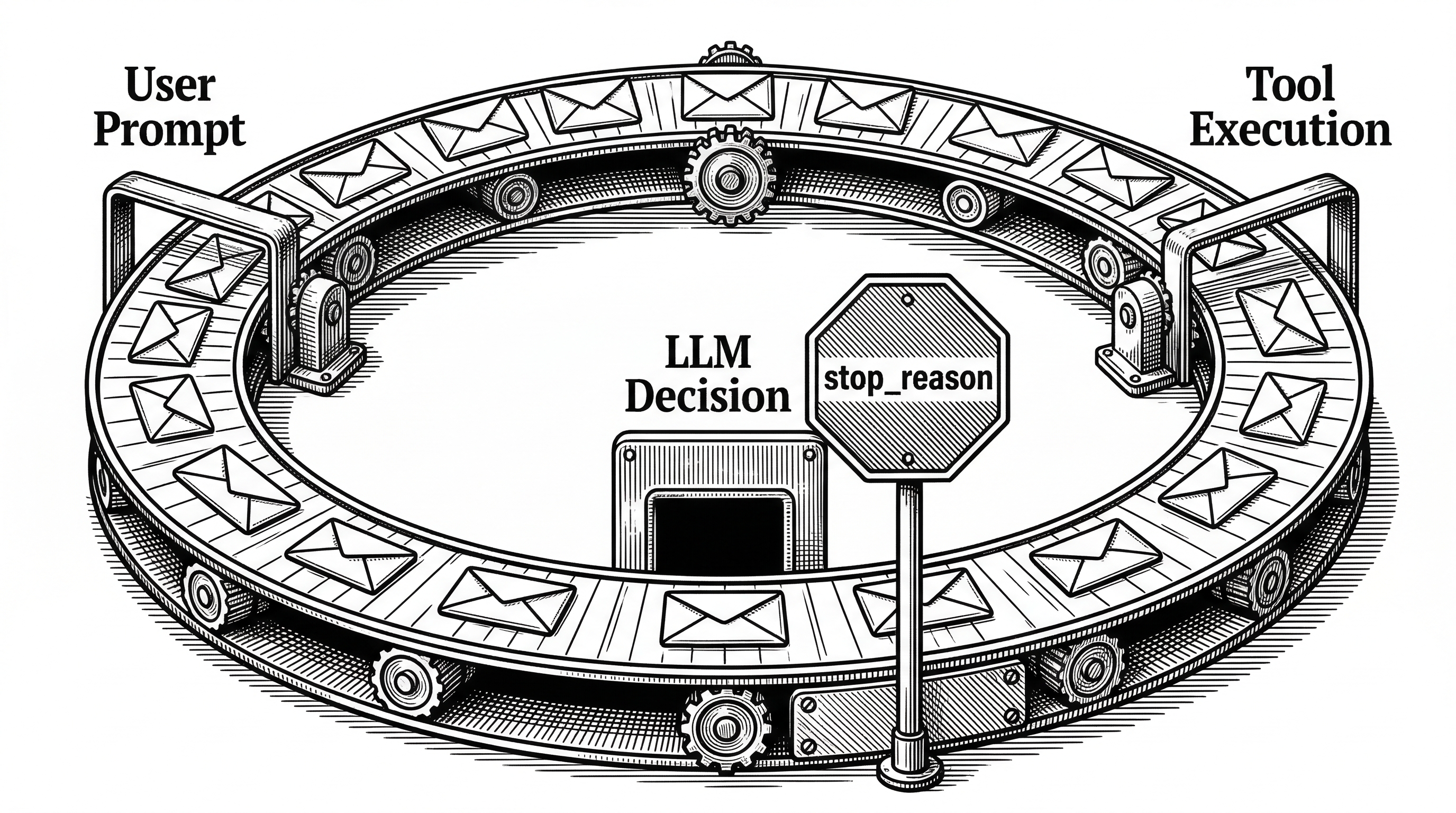
messages.append({"role": "user", "content": results})Call the model. If it wants to use a tool, execute the tool. Feed the result back. Repeat until the model decides it is done. That is an AI coding agent. The model decides what commands to run. The model decides when to stop. The code just executes what the model asks for.
There is no planner module. No state machine. No routing graph. The model is the planner, the state machine, and the router. The code is the hands.
The Harness Equation
If the model is the agent, then what are developers actually building? The answer is the harness. And the repo gives it a clean formula:
"Harness = Tools + Knowledge + Observation + Action Interfaces + Permissions. The model decides. The harness executes. The model is the driver. The harness is the vehicle."
This reframing has real consequences. If you accept that the model is the intelligence and your job is to build the environment it inhabits, you stop trying to engineer cleverness into the orchestration layer. You stop writing elaborate decision trees that try to anticipate every possible path. Instead, you focus on giving the model better tools, cleaner context, and smarter permissions.
The harness for a coding agent is its IDE, terminal, and filesystem access. The harness for a farm agent would be soil sensors, irrigation controls, and weather data. The harness for a hotel agent would be its booking system, guest channels, and facility management APIs. The agent generalizes. The harness specializes.
Building the Vehicle, Session by Session
The twelve sessions form three natural phases. The first phase (s01 through s04) establishes the foundations: the loop, tool dispatch, structured planning, and subagent isolation. The second phase (s05 through s08) handles memory and context: on-demand skill loading, three-layer compression, file-based task graphs, and background execution. The third phase (s09 through s12) tackles multi-agent coordination: teams, protocols, autonomous task claiming, and git worktree isolation.
Each session adds exactly one mechanism. Each mechanism has a motto. "One loop and Bash is all you need." "Adding a tool means adding one handler." "An agent without a plan drifts." The mottos read like proverbs. They are designed to stick in your head after you close the tab.
Tool Dispatch Is Just a Dictionary
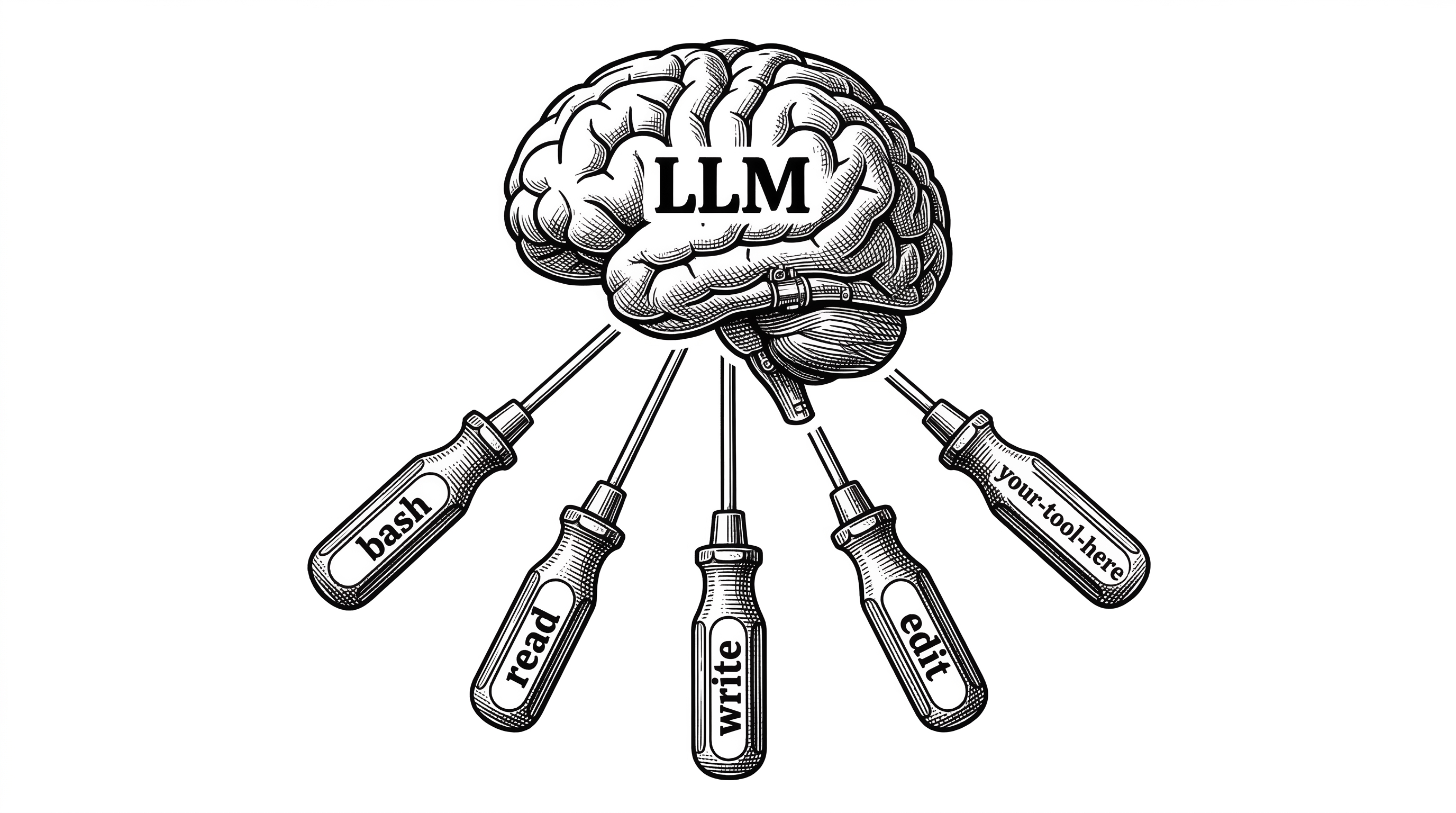
Session 02 is where most frameworks would introduce a registration system, a plugin architecture, or a decorator-based tool API. learn-claude-code introduces a Python dictionary.
TOOL_HANDLERS = {
"bash": run_bash,
"read": run_read,
"write": run_write,
"edit": run_edit,
}
for block in response.content:
if block.type == "tool_use":
handler = TOOL_HANDLERS[block.name]
output = handler(**block.input)The loop does not change. New tools register into the dispatch map. The model picks which tool to call based on the tool descriptions in the API request. That is it. No middleware. No event bus. No lifecycle hooks. Just a dictionary lookup.
This pattern scales further than you might expect. Claude Code itself, the production tool from Anthropic, uses this same dispatch pattern. The tools get more sophisticated (glob, grep, browser), but the mechanism remains a flat map of names to handlers.
Context Is the Real Engineering Problem
Sessions 04 through 06 are where the curriculum gets genuinely interesting. The agent loop is trivial. Tool dispatch is trivial. But keeping a model effective across long sessions, with thousands of tool calls and ballooning message arrays, is the real hard problem.
Session 04 introduces subagents: child agents spawned with a fresh messages array. The child shares the filesystem but gets a clean context. Only a summary returns to the parent. The insight is that process isolation gives context isolation for free. Your main conversation stays clean because the messy exploratory work happens in a disposable child context.
Session 05 flips the conventional wisdom about system prompts. Instead of cramming all domain knowledge into the system message upfront, skills load on demand via tool_result injection. The agent discovers what skills are available and pulls what it needs. Context stays lean.
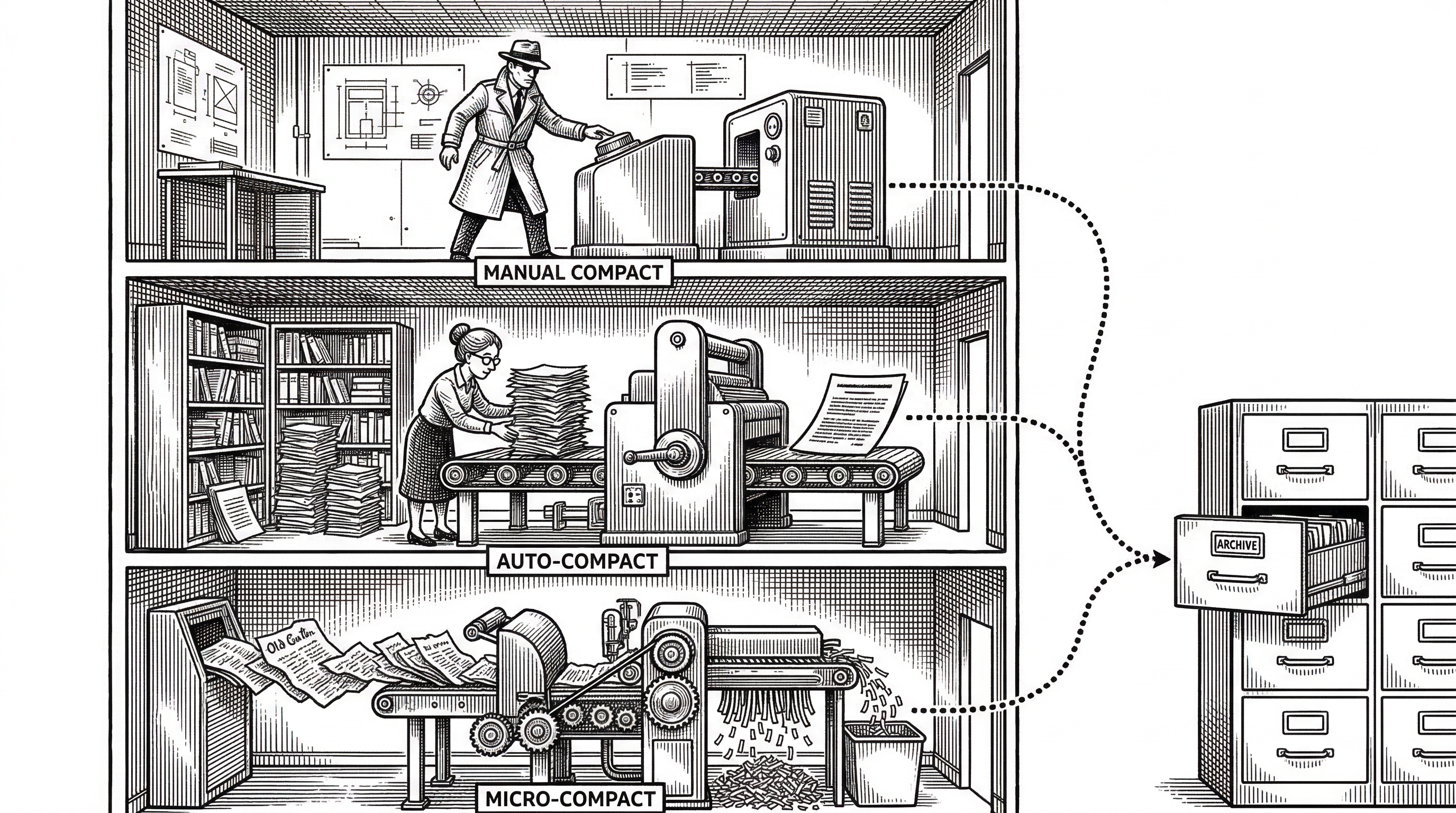
Session 06 is the compression masterpiece. It implements a three-layer strategy. Layer one (micro-compact) silently replaces old tool_result content with short labels on every turn. Layer two (auto-compact) kicks in when tokens exceed a threshold: it saves the full transcript to disk, asks the model to summarize the conversation, and replaces all messages with the summary. Layer three is a manual compact tool the model can call on demand.
The agent can forget strategically and keep working forever. This is the mechanism that separates a demo from a production tool. Without it, every long session would crash into context limits.
From Solo Agent to Autonomous Teams
The final four sessions escalate dramatically. Session 09 introduces persistent teammate agents with async mailboxes under .team/inbox/. Each teammate runs its own agent loop. Communication happens through JSON message files dropped into per-agent inbox directories.
Session 10 standardizes the protocol. One request-response pattern drives all negotiation: messages, broadcasts, shutdown requests, shutdown responses, plan approvals. It is deliberately simple. The complexity of multi-agent coordination emerges from the model's reasoning, not from the protocol's structure.
VALID_MSG_TYPES = {
"message", "broadcast",
"shutdown_request", "shutdown_response",
"plan_approval_response"
}Session 11 is the autonomy payoff. Teammates scan the task board and claim tasks themselves. No assignment from the lead. Idle agents poll for unclaimed work and self-organize around the dependency graph. The lead becomes a coordinator, not a micromanager.
Session 12 closes the loop with directory isolation via git worktrees. Each task gets its own working directory and branch. Tasks are the control plane. Worktrees are the execution plane. They bind together by task ID. Parallel agents never collide because they never share a working directory.
"The model decides. The harness executes. The model reasons. The harness provides context. The model is the driver. The harness is the vehicle."
Why Not Just Use LangChain?
The repo takes a pointed stance against framework-driven agent development. The README calls prompt-chain orchestration libraries "the modern resurrection of GOFAI," the symbolic rule systems the field abandoned decades ago. Strong words. But the technical argument holds up under inspection.
A framework like LangGraph models agent workflows as directed graphs. Nodes are processing steps. Edges define control flow. The developer pre-defines the execution path. The model can only follow paths the developer anticipated. Novel situations break the graph.
The harness pattern inverts this relationship. The model decides the workflow at runtime. The code provides tools and context, then gets out of the way. There is no graph to break because there is no graph. The model's reasoning ability is the graph.
| Aspect | Harness (learn-claude-code) | Framework (LangGraph/CrewAI) |
|---|---|---|
| Core abstraction | While loop + tool dispatch | Directed graph / DAG |
| Who decides workflow | The model, at runtime | The developer, at build time |
| Adding a tool | One dictionary entry | New node + edge wiring |
| Multi-agent coordination | File-based mailboxes + task graph | Framework-managed delegation |
| Context management | Three-layer compression, subagent isolation | Framework state, checkpointing |
| Learning curve | Read 12 Python files | Learn framework API, concepts, config |
| Portability | Works with any LLM API | Often tied to specific providers |
This is not to say frameworks have no value. LangGraph's checkpointing is genuinely useful. CrewAI's role-based prototyping is fast. But the repo's argument is that these features are harness mechanisms, not framework requirements. You can implement checkpointing (session 07's task system) and role-based delegation (session 09's teams) without importing a single library.
The Reverse Engineering That Started It All
learn-claude-code did not emerge from thin air. shareAI-lab completed a full-stack reverse engineering study of Anthropic's Claude Code v1.0.33, analyzing over 50,000 lines of obfuscated JavaScript and TypeScript. They de-obfuscated it and partitioned it into 102 coherent chunks.
What they found validated the harness thesis. Claude Code is one agent loop, plus tools, plus on-demand skill loading, plus context compression, plus subagent spawning, plus a task system with a dependency graph, plus team coordination with async mailboxes, plus worktree isolation, plus permission governance. Every component is a harness mechanism. The intelligence is Claude. The code provides the cockpit.
The twelve sessions in learn-claude-code map directly to the mechanisms they discovered in the reverse engineering. Session 01 corresponds to the core loop. Session 06 corresponds to the /compact command. Session 12 corresponds to Claude Code's worktree system for parallel execution. It is a reconstruction from first principles of what Anthropic built from the production side.

The Capstone: s_full.py
The capstone file, s_full.py, combines every mechanism from sessions 01 through 11 into a single reference implementation. It is not a teaching session. It is the "put it all together" proof that all twelve mechanisms compose cleanly.
Before each LLM call, it runs micro-compact, drains background notifications, and checks the team inbox. The tool dispatch map includes 23 tools: bash, read, write, edit, TodoWrite, task management, skill loading, compression, background execution, teammate spawning, message passing, broadcasting, plan approval, idle polling, and shutdown. REPL commands like /compact, /tasks, /team, and /inbox give the operator direct control.
All of this runs in a single Python file. No imports from framework libraries. No configuration files beyond .env. No build step. The entire harness is visible, editable, and understandable in one sitting.
Skills, Not Just Code
The skills/ directory contains four pre-built skill packages: agent-builder, code-review, mcp-builder, and pdf. Each skill is a markdown file with domain instructions that the model loads on demand via session 05's skill-loading mechanism.
This is a subtle but important architectural choice. Skills are text, not code. They teach the model how to behave in a specific domain by providing context, not by constraining it with programmatic rules. The model reads the instructions and applies them with its own judgment. No enforcement layer. No validation schema. Just natural language guidance injected at the right time.
The Multilingual Bet
The project ships with full documentation in English, Chinese, and Japanese. The README exists in all three languages. The docs/ directory mirrors this structure. The companion web app at learn.shareai.run supports all three locales.
This is not accidental. shareAI-lab is a Chinese open-source organization, and the project's star growth reflects strong adoption across Asian developer communities. The multilingual documentation lowers the barrier for the largest developer populations in the world and explains part of the repo's explosive growth curve.
What the Critics Get Right
The harness-only philosophy has limits. Production deployments need observability, tracing, cost tracking, rate limiting, and retry logic. Claude Code itself has all of these. The twelve sessions do not. They teach architecture, not operational maturity.
The repo also assumes access to frontier models. The agent loop works because Claude and GPT-4 class models are genuinely good at deciding when to call tools and when to stop. Try the same pattern with a weaker model and the loop may spin endlessly or never call a tool at all. The harness is model-agnostic in theory. In practice, it needs a strong model to shine.
There is also a tension between the "no framework" stance and the fact that s_full.py is, itself, a framework. It is a well-designed one with clear boundaries, but it is still 500+ lines of orchestration code that new developers need to understand. The difference from LangChain is a matter of abstraction level, not a matter of kind.
The Bigger Vision
The README ends with a manifesto that extends well beyond coding agents. The harness patterns, the repo argues, apply to any domain: estate management, agriculture, hotel operations, medical research, manufacturing, education. The loop is always the same. The tools change. The knowledge changes. The permissions change. The agent generalizes.
"First we fill the workshops. Then the farms, the hospitals, the factories. Then the cities. Then the planet. Bash is all you need. Real agents are all the universe needs."
Bold? Absolutely. But the technical foundation is sound. If you accept that a frontier LLM is already an agent, then the rate-limiting factor for deploying agents in new domains is not better models. It is better harnesses. Better tools for the model to use. Better knowledge for it to draw on. Better permissions to keep it safe. That is engineering work. And that is exactly what this repo teaches you to do.