OpenDataLoader PDF: The #1 Open-Source PDF Parser That Also Fixes Accessibility
Hancom's Apache 2.0 parser tops extraction benchmarks at 0.90 accuracy, runs 100% locally, and is building the first open-source auto-tagging pipeline to make millions of PDFs accessible before regulators come knocking.
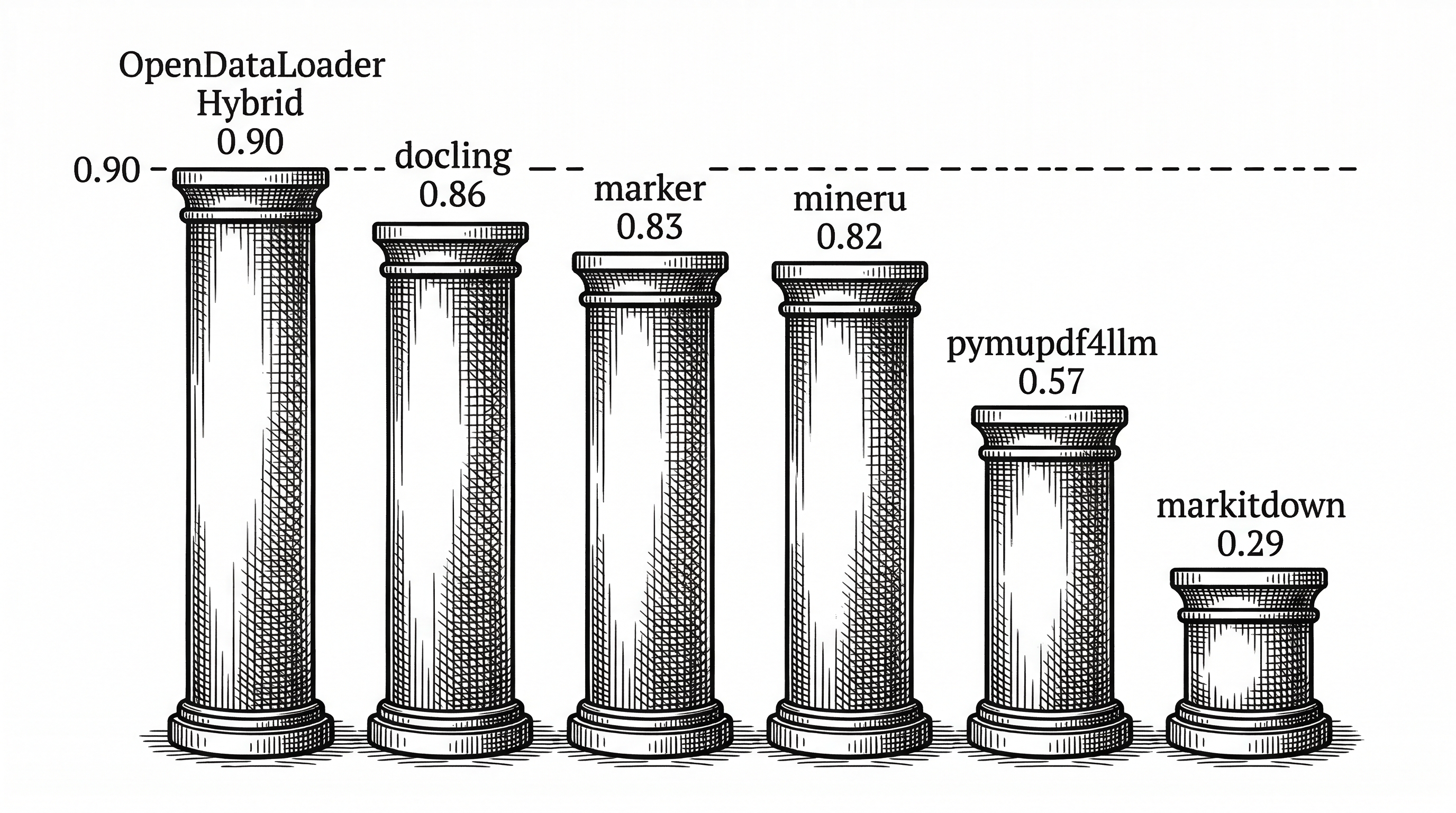
- OpenDataLoader PDF ranks #1 across open-source PDF parsers with 0.90 overall accuracy in hybrid mode, combining deterministic Java extraction with AI backends for complex pages.
- Every extracted element includes bounding box coordinates, enabling "click to source" citation UX in RAG pipelines that competitors like docling and marker cannot match.
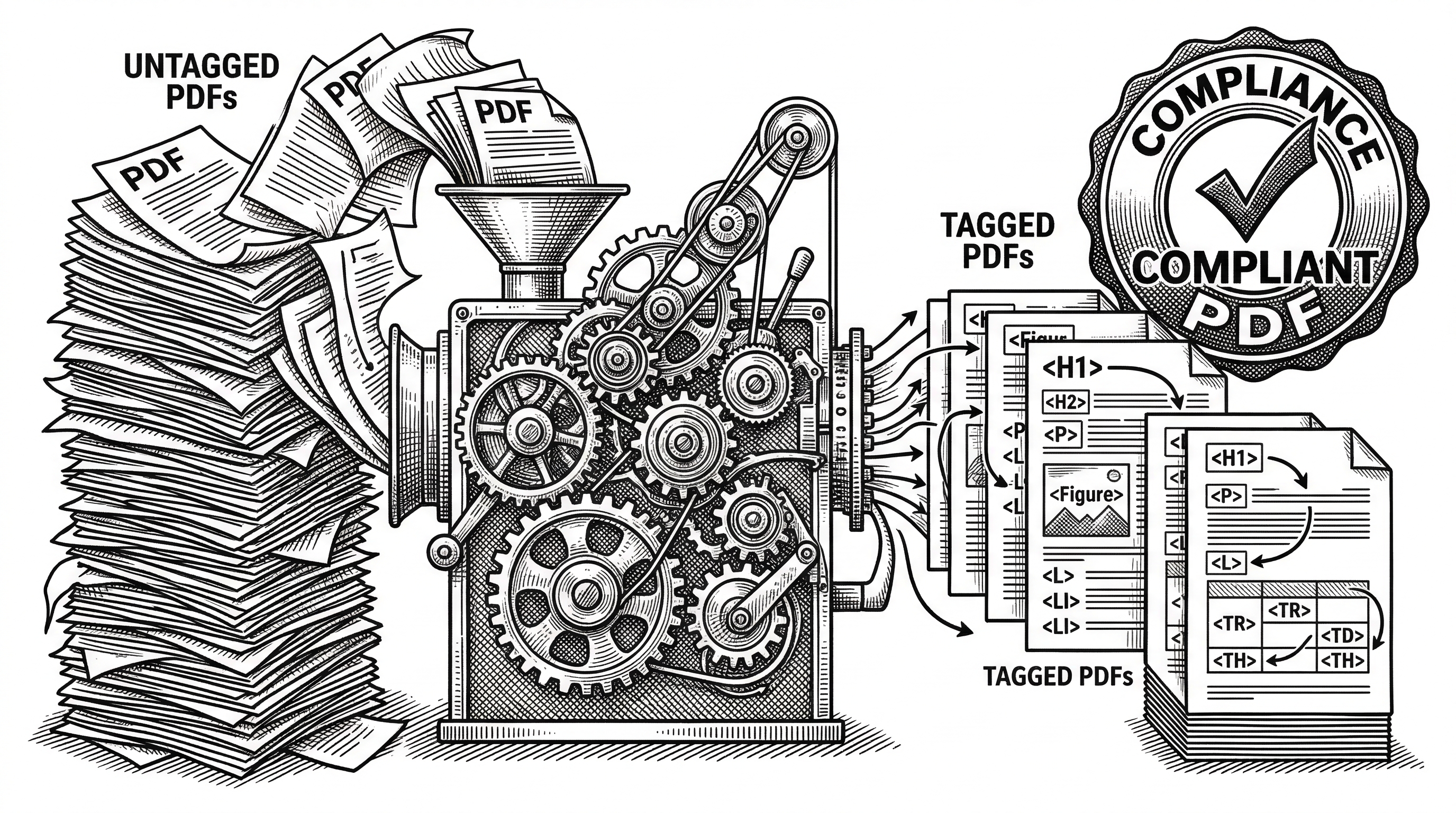
- The same layout analysis engine powers the first open-source PDF auto-tagging pipeline (Q2 2026), turning untagged PDFs into Tagged PDFs under Apache 2.0 with no proprietary SDK dependency.
- Built-in AI safety filters detect prompt injection attacks hidden inside PDFs (transparent text, off-page content, invisible layers), protecting downstream LLMs before they ever see the data.

Two Problems, One Engine
The PDF format is 31 years old and was never designed for machine reading. Every RAG pipeline, every LLM-powered document workflow, every agentic AI system that touches PDFs hits the same wall: the format preserves how a document looks, not what it means.
This creates two distinct but related problems. AI systems need structured data with coordinates and reading order. And hundreds of millions of existing PDFs fail accessibility regulations that are now being enforced worldwide, with penalties reaching 4% of annual revenue.
OpenDataLoader PDF attacks both problems with the same underlying engine. The layout analysis that detects headings, tables, and reading order for data extraction is the same analysis needed to auto-generate accessibility tags. It is a rare case where the technical solution for one problem naturally solves another.
Where It Came From
OpenDataLoader PDF is developed by Hancom, the South Korean enterprise software company. The project was open-sourced in May 2025 and switched from MPL 2.0 to the more permissive Apache 2.0 license. In March 2026, Hancom announced v2.0 with benchmark-topping results and published the full dataset and reproducible code on GitHub.
The timing is not accidental. The European Accessibility Act (EAA) went into effect on June 28, 2025, requiring accessible digital products across the EU. Manual PDF remediation costs $50 to $200 per document. At enterprise scale, that is millions of dollars. Hancom saw an opening to build both the extraction tool AI teams need and the accessibility tool compliance teams need.
"OpenDataLoader PDF v2.0 includes four AI features at no additional cost: OCR, Table Extraction, Formula Extraction, and Chart Analysis."
How It Actually Works
The architecture splits into two modes that share the same Java core.
Local mode is pure deterministic extraction. A Java engine parses the PDF content stream, extracting text, fonts, positions, and structure. The XY-Cut++ algorithm handles layout analysis: detecting headings, paragraphs, tables, lists, images, and reading order. No machine learning. No GPU. No network calls. It processes 20+ pages per second (0.05s per page on Apple M4).
Hybrid mode adds AI backends for pages that need it. A triage step analyzes each page's complexity. Simple pages stay in the fast local path. Complex pages (borderless tables, scanned content, formulas, charts) route to a Python-based AI backend. The backend uses deep learning for table detection (achieving 0.93 TEDS accuracy, up from 0.49 in local mode), OCR for scanned documents in 80+ languages, LaTeX extraction for mathematical formulas, and SmolVLM for chart and image descriptions.
The key insight is that most pages in most PDFs are straightforward. They have clear borders, selectable text, and standard layouts. Only the hard pages need AI. By triaging at the page level, OpenDataLoader keeps the speed of rule-based extraction for the 80% of pages that do not need help, and only pays the AI cost for the 20% that do.
The Bounding Box Advantage
This is the feature that separates OpenDataLoader from every competitor. Every single extracted element (heading, paragraph, table cell, image, formula) comes with a bounding box: four coordinates in PDF points that describe exactly where that element sits on the page.
{
"type": "heading",
"id": 42,
"level": "Title",
"page number": 1,
"bounding box": [72.0, 700.0, 540.0, 730.0],
"heading level": 1,
"content": "Introduction"
}Why does this matter? In a RAG pipeline, when your LLM cites a passage from a PDF, you can map that citation back to the exact bounding box and page. The user clicks a source link and sees the original PDF with the relevant passage highlighted. No guessing, no "somewhere on page 3." This is the "click to source" UX that enterprise RAG deployments require.

Docling, the closest competitor in accuracy (0.86 overall), does not provide bounding boxes. Marker does not either. PyMuPDF4LLM gives basic position information but lacks semantic element typing. OpenDataLoader is the only parser where structured data extraction and spatial coordinates come together in one output.
The Benchmark Picture
Hancom published full benchmarks across 200 real-world PDFs including multi-column layouts, scientific papers, financial reports, and government documents. The test code and dataset are open on GitHub for independent reproduction.
| Engine | Overall | Reading Order | Table (TEDS) | Heading | Speed (s/page) |
|---|---|---|---|---|---|
| OpenDataLoader [hybrid] | 0.90 | 0.94 | 0.93 | 0.83 | 0.43 |
| docling | 0.86 | 0.90 | 0.89 | 0.80 | 0.73 |
| marker | 0.83 | 0.89 | 0.81 | 0.80 | 53.93 |
| mineru | 0.82 | 0.86 | 0.87 | 0.74 | 5.96 |
| OpenDataLoader [local] | 0.72 | 0.91 | 0.49 | 0.76 | 0.05 |
| pymupdf4llm | 0.57 | 0.89 | 0.40 | 0.41 | 0.09 |
| markitdown | 0.29 | 0.88 | 0.00 | 0.00 | 0.04 |
A few things jump out. The table extraction gap is dramatic: 0.93 in hybrid mode versus 0.49 in local mode. That is almost a 2x improvement. For documents heavy on complex tables (financial reports, scientific data), this alone justifies the hybrid approach.
Speed matters too. Marker requires a GPU and still takes 53.93 seconds per page. OpenDataLoader hybrid runs at 0.43 seconds per page. OpenDataLoader local runs at 0.05 seconds per page. In a production pipeline processing thousands of documents, that speed difference compounds fast.
How It Compares to Alternatives
The PDF parsing landscape has gotten crowded. Here is how OpenDataLoader stacks up against the main players.
Docling (IBM, 0.86 overall): The strongest competitor on accuracy. Good for air-gapped RAG systems. But no bounding boxes in output, no built-in AI safety filters, and slower at 0.73s per page. If you do not need coordinates or security filtering, docling is solid.
Marker (0.83 overall): Uses Surya OCR for multilingual extraction. Supports GPU, CPU, and Apple MPS. But 53.93s per page makes it impractical for batch processing. Better suited for small-scale, high-quality extraction where speed does not matter.
MinerU (0.82 overall): Strong table extraction (0.87) but slower at 5.96s per page. Good middle ground if you need better-than-local accuracy without the full OpenDataLoader hybrid setup.
PyMuPDF4LLM (0.57 overall): Extremely fast (0.09s/page) but poor accuracy on tables (0.40) and headings (0.41). Fine for simple, single-column text extraction where structure does not matter.
Markitdown (Microsoft, 0.29 overall): Fast but zero table and heading accuracy. Useful only for basic text extraction from simple PDFs. Not a serious option for structured data.
AI Safety: A Quiet Killer Feature
PDFs can contain hidden content designed to attack LLMs. Transparent text that humans cannot see but models read. Off-page content placed outside the visible area. Zero-size fonts that carry hidden instructions. These are real prompt injection vectors, and most PDF parsers pass them straight through.
OpenDataLoader automatically filters these attacks. Hidden text, transparent fonts, off-page content, and suspicious invisible layers are all caught and removed before the extracted content reaches your pipeline. No configuration needed. It is on by default.
For pipelines that process untrusted PDFs (legal discovery, customer uploads, web scraped documents), this is not a nice-to-have. It is a security requirement. The alternative is building your own post-processing layer to detect and remove these attacks, which is exactly the kind of thing that gets skipped under deadline pressure.
There is also a data sanitization mode that replaces emails, phone numbers, IP addresses, credit card numbers, and URLs with placeholders. Useful for compliance-sensitive workflows where PII in extracted text creates liability.
Three Lines to Structured Data
The developer experience is deliberately simple. Python, Node.js, and Java SDKs all follow the same pattern.
import opendataloader_pdf
opendataloader_pdf.convert(
input_path=["file1.pdf", "file2.pdf", "folder/"],
output_dir="output/",
format="markdown,json"
)One important detail: each convert() call spawns a JVM process. Repeated calls are slow. Batch all your files into a single call. This is a common gotcha for developers coming from pure Python libraries where per-file calls are natural.
For hybrid mode, you start a local backend server, then point the client at it.
# Terminal 1: start the AI backend
opendataloader-pdf-hybrid --port 5002
# Terminal 2: process with hybrid mode
opendataloader-pdf --hybrid docling-fast file1.pdf file2.pdf folder/Everything runs locally. No cloud API calls, no data leaving your machine. For legal, healthcare, and financial documents, this is a hard requirement that cloud-based extraction services cannot meet.

The Accessibility Bet
Here is where OpenDataLoader gets genuinely interesting beyond just being another PDF parser.
The European Accessibility Act went into effect in June 2025. ADA and Section 508 have been enforced in the US for years. South Korea's Digital Inclusion Act adds more pressure in Asia. Non-compliance penalties can reach 4% of annual revenue. Organizations suddenly have millions of existing PDFs that need accessibility tags, and manual remediation at $50 to $200 per document is financially impossible at scale.
OpenDataLoader's approach: use the same layout analysis engine that powers data extraction to automatically generate accessibility structure tags. Untagged PDF in, Tagged PDF out. The auto-tagging feature is coming in Q2 2026 under the free Apache 2.0 license.
The pipeline has four stages. Stage 1 (Audit) is shipped: read existing tags, detect untagged PDFs. Stage 2 (Auto-Tag) is coming Q2 2026 under Apache 2.0: generate Tagged PDF from untagged input. Stage 3 (PDF/UA Export) is enterprise: convert to PDF/UA-1 or PDF/UA-2 compliance format. Stage 4 (Visual Editor) is enterprise: Accessibility Studio for manual review and fixes.
No existing open-source tool generates Tagged PDFs end-to-end. Most accessibility tools rely on proprietary SDKs for the tag-writing step. OpenDataLoader is building the entire pipeline from layout analysis through tag generation under an open license.
The PDF Association Partnership
What gives the accessibility story credibility is the collaboration partners. OpenDataLoader's auto-tagging follows the Well-Tagged PDF specification from the PDF Association, the organization that maintains the PDF standard itself. Validation is done using veraPDF, the industry-reference open-source PDF/A and PDF/UA validator, developed by Dual Lab.
This is not a solo effort. The PDF Association endorsed OpenDataLoader v2.0 on their official site. Dual Lab co-develops the tagging and validation pipeline. Having the standards body and the reference validator involved from the start means the auto-tagging output should actually pass compliance checks, not just look like it does.
"Auto-tagging follows the Well-Tagged PDF specification and is validated programmatically using veraPDF. Automated conformance checks against PDF accessibility standards, not manual review."
Tagged PDF Support: The Underrated Feature
Most PDF parsers ignore structure tags entirely. When a PDF author or tool has already tagged a document with semantic structure (headings, lists, tables, reading order), those tags represent the author's intent. Throwing them away and guessing the structure from visual layout is wasteful at best and wrong at worst.
OpenDataLoader reads existing structure tags when you enable use_struct_tree=True. This means for Tagged PDFs, you get the exact layout the author intended. No heuristics needed. The reading order, heading levels, table structure, and list nesting are all preserved from the source.
This matters particularly for government documents, academic papers, and corporate reports that are increasingly published as Tagged PDFs. Your extraction quality for these documents jumps significantly with one flag.
The Java Foundation
The choice of Java for the core engine is deliberate. Java's PDF libraries (built on Apache PDFBox internals) are mature and battle-tested. The JVM provides consistent cross-platform behavior. And the rule-based extraction approach means no model weights, no GPU dependencies, and no Python packaging headaches for the core path.
The Python and Node.js SDKs are wrappers that spawn the Java process. This explains the "batch everything in one call" pattern: the JVM startup cost is real. It is a tradeoff. You get proven PDF parsing technology and cross-platform reliability. You pay a startup cost per invocation.
The hybrid backend, by contrast, is Python. Deep learning table detection, OCR, formula extraction, and vision models all run in the Python ecosystem where those tools are strongest. The architecture plays to each language's strengths.
What is Missing
OpenDataLoader is not without limitations. It only processes PDFs. No Word, Excel, or PowerPoint support. If your pipeline handles mixed document types, you need a separate tool for non-PDF formats.
The JVM startup cost per convert() call means it does not work well for on-demand, single-file processing where latency matters. Batch workloads are the sweet spot.
The auto-tagging feature is not shipped yet. The Q2 2026 timeline means it is still months away. The accessibility story is compelling in theory, but the free tier only covers the auto-tagging step. PDF/UA export (the part that actually produces regulation-compliant output) requires the enterprise tier.
The benchmark results are self-published. Hancom did release the dataset and code for reproduction, which is good practice. But independent third-party validation of the numbers would strengthen the claims. The open benchmark repository helps here.
Finally, the 3,000-star count, while growing, is modest compared to established tools. The project is less than a year old. Community ecosystem (plugins, integrations, Stack Overflow answers) is still thin.
Who Should Use This
RAG pipeline builders who need bounding boxes for citation grounding. This is the primary differentiator. If your RAG system needs to show users exactly where an answer came from in the original PDF, OpenDataLoader is the only open-source option that gives you coordinates for every element.
Compliance teams facing accessibility deadlines. Once auto-tagging ships, this becomes the only open-source path from untagged PDF to Tagged PDF. The enterprise PDF/UA export adds the final compliance step.
Security-conscious organizations processing untrusted PDFs. The built-in prompt injection filtering means one less thing to build and maintain in your pipeline.
High-volume batch processors. The 0.05s/page local mode and 0.43s/page hybrid mode make this practical for document-heavy workflows. Legal discovery, insurance claims, financial document processing.
The Bigger Picture
OpenDataLoader PDF is interesting because it sits at the intersection of two massive trends. The AI data pipeline trend needs better PDF extraction for RAG, agents, and fine-tuning. The accessibility compliance trend needs automated remediation before regulators levy real fines.
Hancom's bet is that the same core technology (layout analysis and structure detection) serves both markets. The open-source extraction engine builds community and adoption. The accessibility pipeline creates enterprise revenue. The Hancom Data Loader integration (coming Q2-Q3 2026) adds customer-customized AI models for domain-specific documents.
Whether OpenDataLoader becomes the standard PDF parser for AI pipelines depends on whether the community develops around it. The benchmarks are strong. The bounding box feature is unique. The accessibility angle is timely. The Apache 2.0 license removes adoption friction. But it is still early. The project needs more integrations (LlamaIndex, Gemini CLI, and MCP support are planned), more community contributors, and the auto-tagging feature to actually ship.
For now, if you need structured PDF data with coordinates and you care about security, OpenDataLoader is the strongest open-source option available. If you also have accessibility compliance on your roadmap, it might be the only tool you need.