OpenViking Treats Agent Memory Like a Filesystem and Cuts Token Costs by 95%
ByteDance's open-source context database replaces flat vector storage with a hierarchical virtual filesystem, tiered L0/L1/L2 loading, and directory recursive retrieval to give AI agents structured, affordable long-term memory.

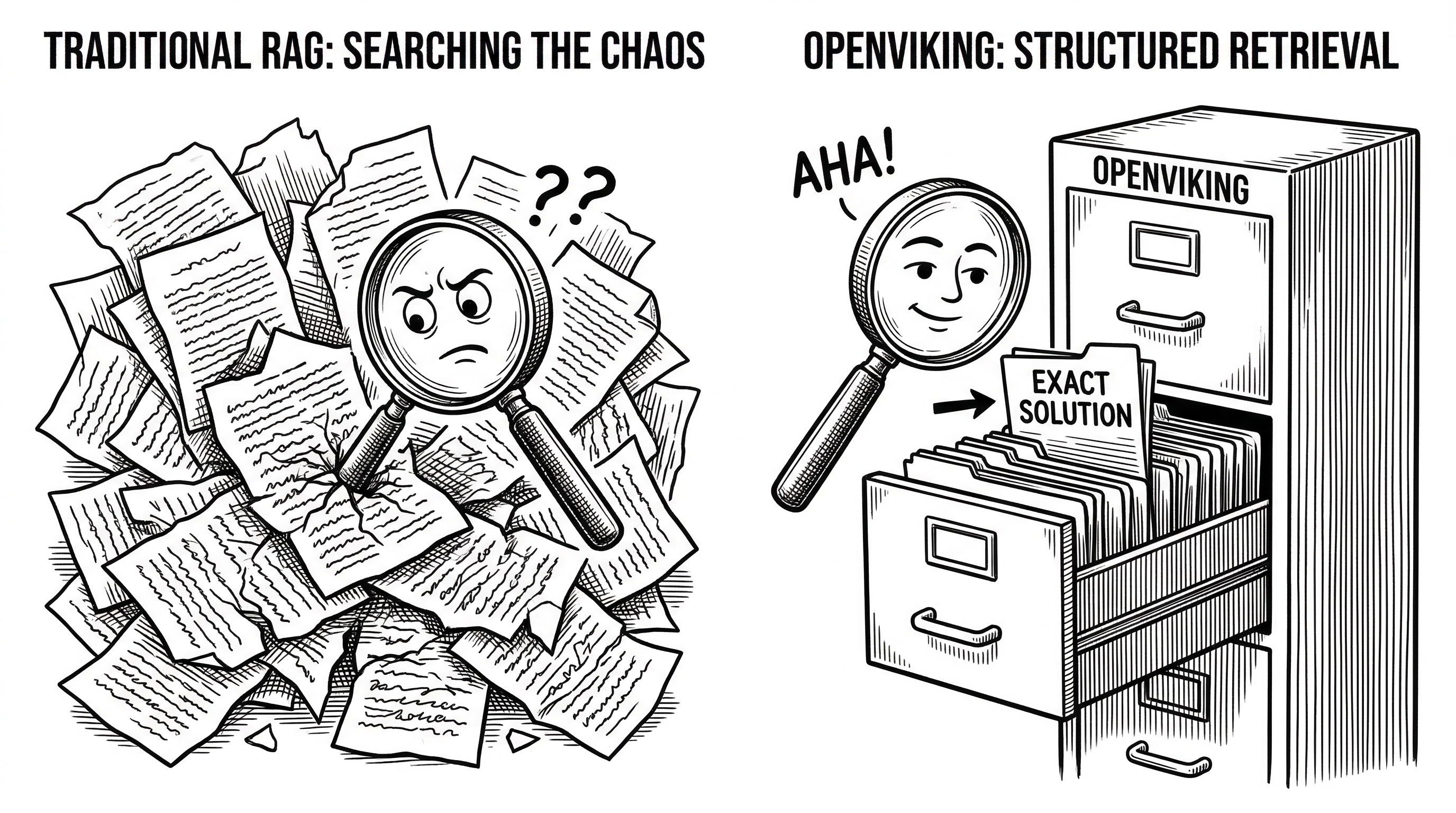
- OpenViking replaces the flat vector dumps of traditional RAG with a virtual filesystem that organizes agent memory, resources, and skills into a navigable directory tree under the viking:// protocol.
- Its L0/L1/L2 tiered context loading delivers an average of 550 tokens per retrieval instead of 10,000, cutting inference costs by up to 95%.
- Directory recursive retrieval combines vector search with hierarchical drill-down, preserving both semantic relevance and the structural relationships that flat retrieval destroys.
- At 15.3k stars in under three months and official plugins for OpenClaw and Claude, OpenViking is quickly becoming the default memory backend for the agentic stack.
The Problem Nobody Solved Cleanly
Every serious agent builder hits the same wall. The agent can reason, plan, and use tools, but it forgets everything between sessions. Memories live in one place, project documents in another, skills in a third. There is no unified way to store, organize, or retrieve the context an agent needs to do its job.
The standard fix has been some flavor of RAG: chunk your data, embed it, throw it in a vector database, and pray the top-k results contain what the model actually needs. This works for simple Q&A. It falls apart for agents running complex, multi-step tasks over long time horizons.
The core issues are well-documented. Flat vector storage has no concept of hierarchy or relationships between chunks. Retrieval is a black box that is nearly impossible to debug. And every query dumps a fixed amount of context into the LLM window regardless of whether the agent needs a one-sentence summary or a full technical document.
ByteDance's Volcengine team decided to rethink the problem from scratch. Their answer: stop treating agent context like a bag of vectors and start treating it like a filesystem.
The Filesystem Paradigm
OpenViking's central insight is that a filesystem is the most natural abstraction for organizing knowledge. Developers already know how to think in directories, files, and paths. Why force them to learn a new mental model just because the data is going to an AI agent?
Everything in OpenViking lives under the viking:// protocol. Three top-level directories map to the three types of context an agent needs:
- resources/ holds project documentation, configuration files, API specs, and external data. Think of it as the agent's reference library.
- user/ stores personal preferences, conversation histories, and extracted memories. Short-term and long-term memories live in separate subdirectories.
- agent/ contains skills, instructions, and task memories. This is where the agent's learned capabilities accumulate over time.
The agent interacts with this tree using familiar filesystem operations: ls, read, write, find, and rm. Under the hood, these operations route through VikingFS, an abstraction layer built on the Agent Global File System (AGFS) storage backend. But from the agent's perspective, it is just browsing folders.
This is not merely an organizational convenience. The directory structure creates a semantic hierarchy that the retrieval system exploits. When an agent searches for "deployment config for Kubernetes," the system does not blindly scan every chunk in the database. It uses the tree structure to narrow down to the right neighborhood first, then retrieves within it.
L0/L1/L2: The Tier System That Saves 95%
The filesystem paradigm solves the organization problem. The tiered loading system solves the cost problem.
Every piece of context in OpenViking exists at three levels of detail. L0 is a one-sentence abstract, roughly 100 tokens. L1 is an overview with core information and usage scenarios, around 2,000 tokens. L2 is the full original content, which can run to 10,000 tokens or more.
When an agent queries the context database, OpenViking starts at L0. The agent scans these lightweight summaries to decide which items deserve a closer look. If it needs more detail, it requests L1. Only when deep reading is truly necessary does it pull L2.
The result is dramatic. Traditional vector retrieval loads around 10,000 tokens upfront for every query. OpenViking averages 550 tokens. That is a 95% reduction in token consumption, which translates directly to cost savings on inference.
This is not just about money. Smaller context windows mean faster inference, less hallucination from irrelevant context, and better signal-to-noise ratio in the information the model actually sees. The agent makes better decisions because it is not drowning in data it does not need.
"OpenViking loads 550 tokens on average compared to traditional vector search loading 10,000 tokens upfront. The tiered approach lets agents decide how deep to go rather than forcing a fixed context size."
Directory Recursive Retrieval
The retrieval mechanism is where the filesystem paradigm and the tier system come together. OpenViking calls it Directory Recursive Retrieval, and it works like a human navigating a well-organized file structure.
Step one: a vector search across the top-level directories identifies which branch of the tree is most relevant to the query. Step two: within that directory, a second retrieval narrows the focus to the right subdirectory. Step three: the system recursively drills down until it reaches the specific context items that match.
This preserves something flat vector search destroys: the structural relationship between pieces of information. A Kubernetes deployment config lives in context with the Docker configs and CI/CD files in its parent directory. The retrieval system knows they are related because the filesystem says so. No fancy graph database required.
OpenViking also makes this process observable. You can visualize the retrieval trajectory to see exactly which directories the system traversed and why it made each decision. When retrieval goes wrong, you can see the root cause instead of staring at a black-box similarity score.
Session Memory That Evolves
Static retrieval is only half the story. Agents that run across multiple sessions need their memory to grow and improve over time. OpenViking handles this through automatic session management.
After each conversation, the session module compresses the interaction, extracts references to resources and tool calls, and identifies long-term memories worth keeping. These extracted memories get filed into the user/memories/long-term/ directory. The agent literally gets smarter with use because its filesystem grows with relevant context.
The session pipeline includes a compressor that reduces verbose conversations to their essential content, a memory extractor that identifies facts and preferences worth persisting, and a deduplicator that prevents the same information from cluttering the tree. A memory archiver handles the lifecycle of aging memories, ensuring the filesystem stays useful rather than becoming a dumping ground.
This is a meaningful departure from competitors. Most agent memory systems treat memory as a log of past interactions or a flat set of extracted facts. OpenViking treats memory as living data with a lifecycle, organized within the same filesystem structure as everything else.
The Architecture Under the Hood
OpenViking's codebase is primarily Python (about 83% by volume), with C++ for performance-critical index operations and Rust for the CLI tooling. The architecture splits into several clean modules.
The core module handles the fundamental abstractions: building the directory tree, managing context objects, loading skills, and converting between MCP (Model Context Protocol) formats. The retrieve module implements the hierarchical retriever, intent analyzer, memory lifecycle management, and retrieval statistics. The storage layer provides the VikingFS virtual filesystem, vector database adapters, and transaction support.
The server exposes a REST API with authentication, multi-tenant support, and telemetry. You can run it locally or deploy it on Kubernetes using the provided Helm charts. A Docker Compose file gets you up and running for development in minutes.
pip install openviking --upgrade --force-reinstallFor the CLI, there is a Rust-based tool that installs via curl or cargo:
curl -fsSL https://raw.githubusercontent.com/volcengine/OpenViking/main/crates/ov_cli/install.sh | bashModel support is broad. OpenViking needs a VLM (for content understanding) and an embedding model (for vectorization). It supports Volcengine's Doubao models, OpenAI, and any provider accessible through LiteLLM, which covers Anthropic, DeepSeek, Gemini, Ollama, vLLM, and dozens more.
How It Stacks Up
The agent memory space has exploded in 2026. Mem0, Zep, Letta, Cognee, and a growing list of alternatives all tackle some version of the "agents need persistent memory" problem. OpenViking's positioning is distinct in two ways: the filesystem paradigm and the tiered loading.
| Aspect | OpenViking | Mem0 | Zep | Letta |
|---|---|---|---|---|
| Core Paradigm | Hierarchical filesystem | Memory extraction layer | Temporal knowledge graph | Self-editing agent memory |
| Context Loading | Tiered L0/L1/L2 | Flat retrieval | Graph traversal | Agent-managed windows |
| Token Efficiency | ~550 avg (95% reduction) | Standard RAG costs | Moderate | Agent-dependent |
| Observability | Visualized retrieval paths | Basic logging | Graph visualization | Memory inspection |
| Unified Context | Memory + resources + skills | Memory focused | Conversation focused | Full agent state |
| Backing | ByteDance / Volcengine | VC-funded startup | VC-funded startup | VC-funded startup |
Mem0 excels at extracting and personalizing memories from interactions. Zep's temporal knowledge graph tracks how facts change over time. Letta gives agents direct control over their own memory management. Each has real strengths.
But none of them unify memory, resources, and skills into a single navigable structure. And none offer the progressive disclosure that L0/L1/L2 provides. If your agent needs to manage a complex project with documentation, configurations, user preferences, and accumulated task knowledge, the filesystem metaphor is hard to beat.
The OpenClaw Connection
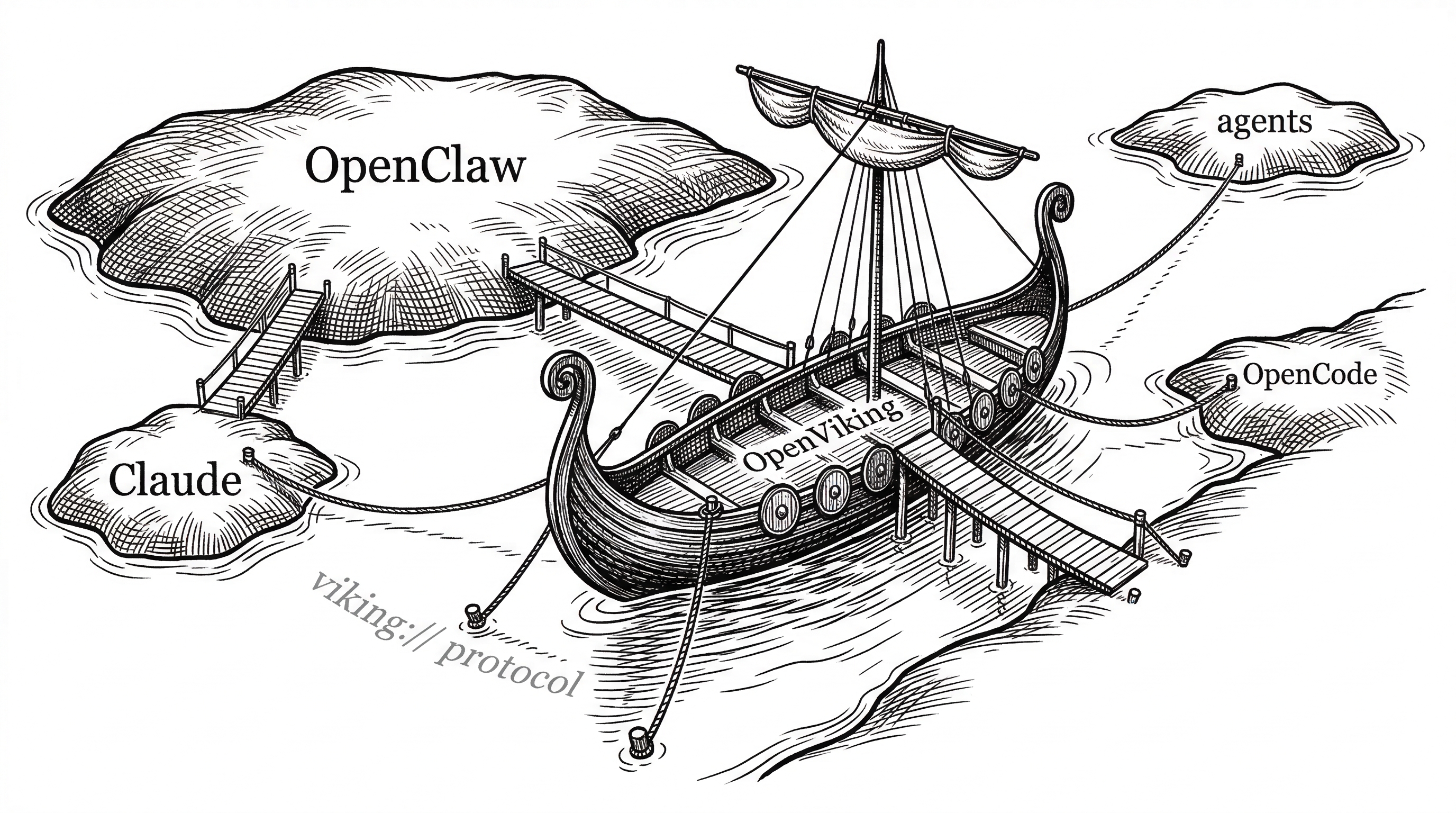
OpenViking was designed alongside OpenClaw, ByteDance's autonomous agent framework that has become one of the fastest-growing open source projects in history. The two projects are complementary: OpenClaw handles agent orchestration and execution, OpenViking handles the memory and context layer.
An official openclaw-memory-plugin lets you plug OpenViking directly into an OpenClaw agent as its long-term memory backend. Once installed, the agent automatically remembers important information from conversations and recalls relevant context before responding. There are also plugins for Claude and OpenCode.
The plugin architecture makes it clear that OpenViking is not trying to be a full agent framework. It is infrastructure. It wants to be the context layer that any agent system can plug into, the same way PostgreSQL does not care whether you access it from Django or Rails.
What Actually Ships
Let us be concrete about what you get when you install OpenViking today.
The Python package gives you the full server, client libraries (sync and async), the VikingFS abstraction, the hierarchical retriever, session management, and the evaluation framework. The Rust CLI provides a fast command-line interface for managing context outside of Python.
The examples directory includes quickstart scripts, server-client demos, MCP query examples, multi-tenant configurations, Kubernetes Helm charts, and the plugin integrations for OpenClaw, Claude, and OpenCode. The skill system lets you define reusable agent capabilities as files in the filesystem, making them discoverable and versionable alongside everything else.
Documentation is solid, with English and Chinese versions covering architecture, API reference, and deployment guides. The project has 30 contributors, active development (pushed just yesterday as of this writing), and a growing community across Discord, Lark, and WeChat.
The Skeptic's Questions
Is the filesystem metaphor too rigid? Hierarchies work well for data that naturally nests, like project documentation and configuration. They work less well for cross-cutting concerns. If a memory is relevant to both a user preference and a project config, where does it live? OpenViking handles this through tagging and semantic search that can cross directory boundaries, but the primary organization remains hierarchical.
What about the ByteDance dependency? The project is Apache 2.0 licensed and genuinely open source. But the default configuration points to Volcengine's model services, and the embedding layer has first-class support for ByteDance's Doubao models. The LiteLLM integration means you can use any provider, but the gravity pulls toward the Volcengine ecosystem. This is the standard playbook: open source the infrastructure, monetize the cloud services.
Can the 95% cost reduction claim hold up in practice? It depends entirely on the query distribution. If most agent queries can be satisfied with L0 or L1 context, the savings are real. If your use case consistently requires L2 full-document retrieval, you are back to standard costs. The 550-token average is a benchmark number, not a guarantee.
Where This Goes
OpenViking is two months old and already has 15,000+ stars. The trajectory suggests it is filling a real gap in the agentic stack. As agents move from demos to production, the need for structured, cost-effective, observable context management will only grow.
The filesystem paradigm is a strong bet. It is intuitive, debuggable, and composable. The tiered loading is a genuine innovation that addresses the economic reality of running agents at scale. And the ByteDance backing means this project has the engineering resources to keep up with the breakneck pace of the agent ecosystem.
Whether OpenViking becomes the default context layer for AI agents or just one strong option among many, it has already shifted the conversation. The question is no longer "should agents have persistent memory?" It is "how should that memory be organized?" OpenViking's answer is the one developers already know: like files in a filesystem.